学在西电录播课使用python下载,通过解析m3u8协议、多线程下载ts视频块以及ffmpeg合并
本文涵盖的内容仅供个人学习使用,如果侵犯学校权利,麻烦联系我删除。
初衷
研究生必修选逃, 期末复习怕漏过重点题目,但是看学在西电的录播回放课一卡一卡的,于是想在空余时间一个个下载下来,然后到时候就突击复习。
环境
因为懒得用二进制安装ffmpeg,所以用的Ubuntu22.04
1
2
3
4
5
6
7
8
| sudo apt install ffmpeg
ffmpeg -version
# 要有python3,安装步骤略过
...
# pip依赖
pip install aiohttp
pip install tqdm
pip install m3u8
|
预备知识
关于网站部分,本文写于2024-12-05,不保证后面会不会改
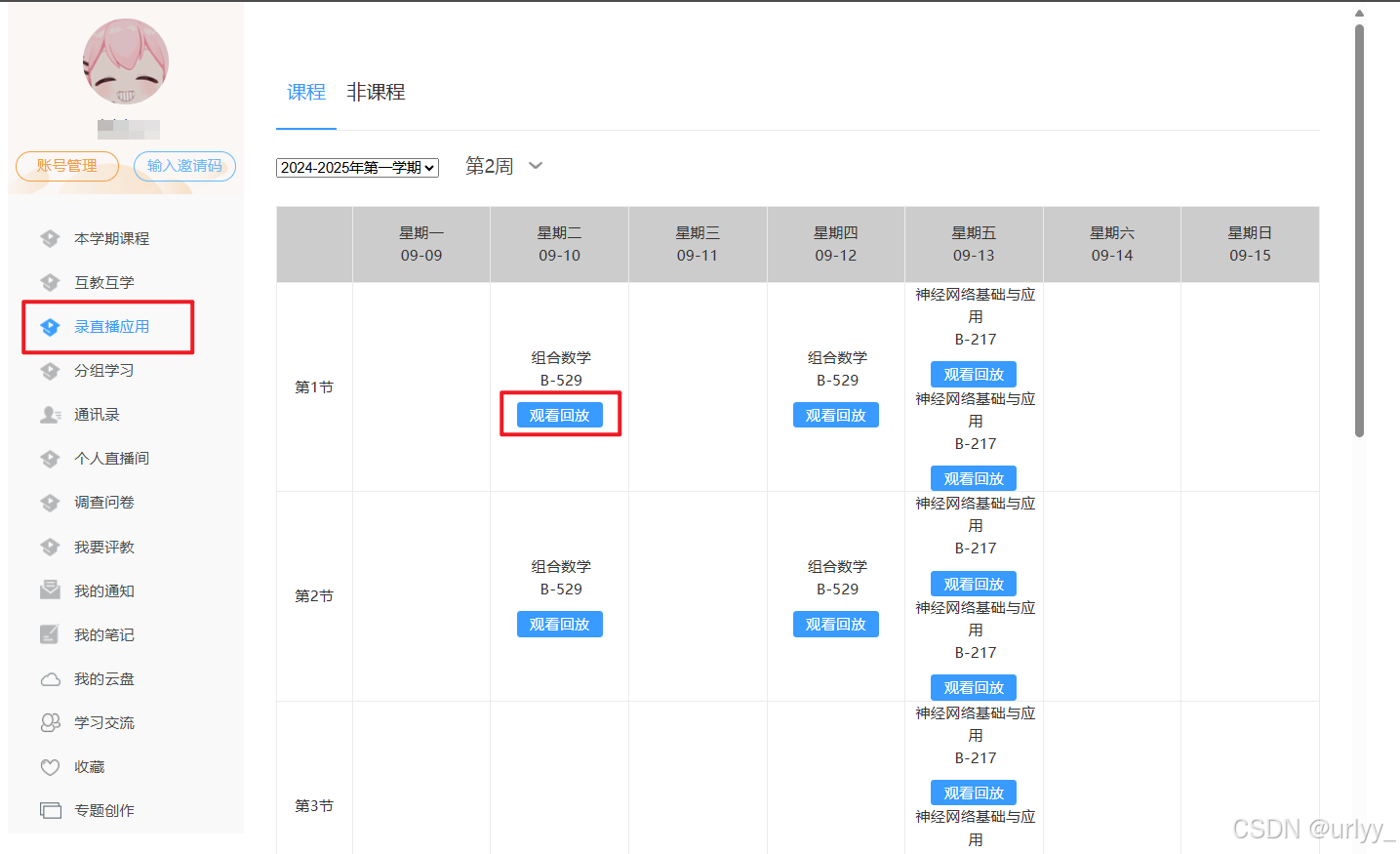
学在西电就是在学习通上再加了一层,加了点新东西。录播在这个地方看。(本文默认已经登录成功)

下面的图就是录播播放界面,由于有学生姓名和学号的水印,我打码了。
左边是拍老师和黑板的录像,右边是展示ppt的录像。
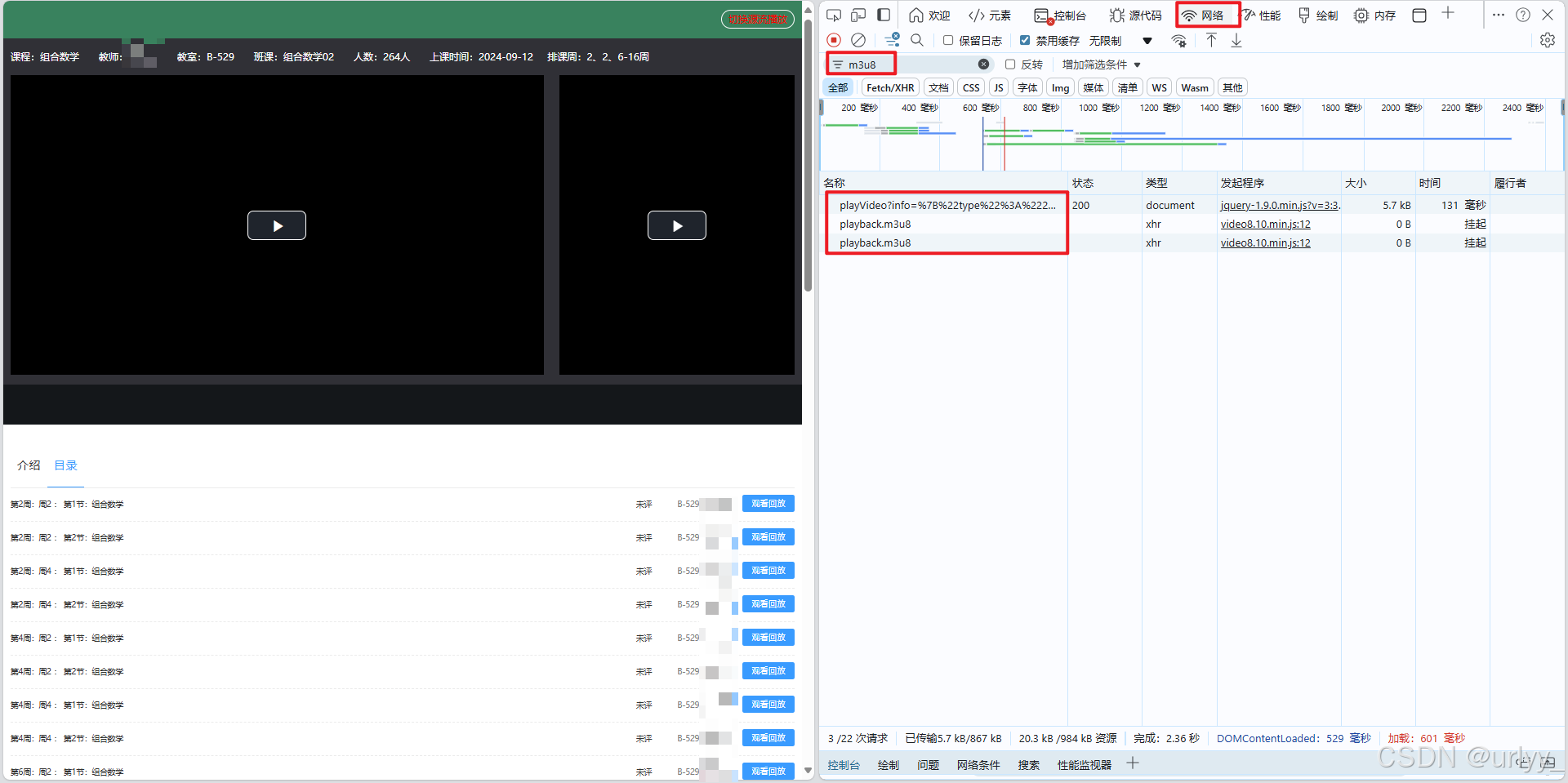
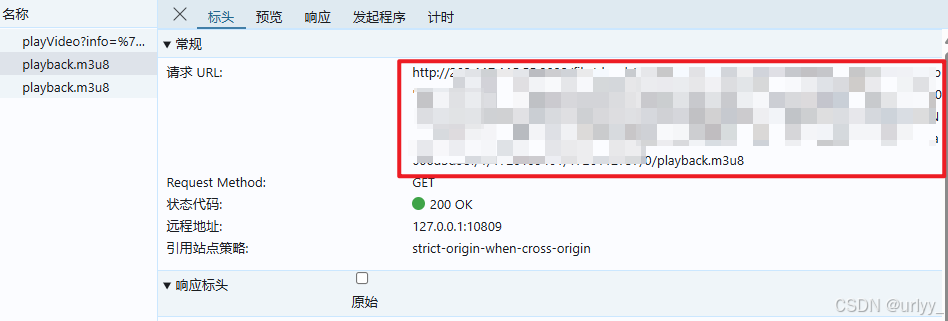
为了捕获请求,我们先打开开发者面板的网络面板,点击下面的某堂课跳转,然后在页面刷新后获取到加载时的请求,通过关键词过滤m3u8,得到重要的三个请求。
注意这里有两个playback.m3u8,通过上面图中那个另外的请求playVideo?info=...的响应,我们可以看到pptVideo和teacherTrack这两个路径,分别对应ppt和老师黑板的m3u8文件的url。
1
2
3
4
5
6
7
8
9
10
| {
"type": "2",
"videoPath": {
"pptVideo": "....m3u8",
"teacherTrack": "....m3u8",
"studentFull": "....m3u8"
},
"liveId": ...,
"isshowpl": 0
}
|
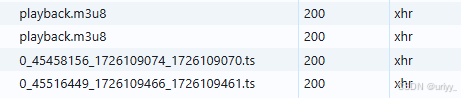
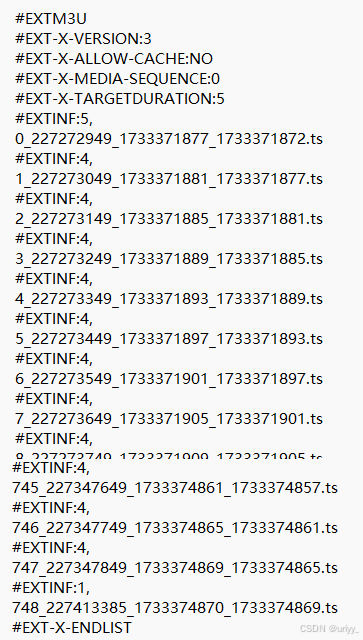
在学在西电里,视频文件是被切分为许多个几秒的视频块(ts文件,是Transport Stream不是Typescript),通过一个m3u8协议文件保存对应视频的各个小视频块的文件名、序列号、持续时间等信息。
m3u8文件内容如下,还好学在西电这里没有做加密,没有#EXT-X-KEY:METHOD=AES-128,URI...这么一行,所以我们可以用这些ts文件名直接下载(当然前面还要有http之类的前缀)。
最后,使用伟大牛逼的 ffmpeg 可以将这些ts文件合并为 mp4 文件。
具体代码
1. 下载各ts
基于m3u8库解析m3u8文件,aiohttp做协程下载,tqdm做进度条方便查看,最后记得threading加锁。
考虑到偶尔的下载异常,加了个2次重试。
url按照下图获取
实测5分钟左右下完。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| import shutil
import threading
import m3u8
import os
import logging
import re
import asyncio
import aiohttp
from tqdm import tqdm
pbar:tqdm = None
pbar_lock = threading.Lock()
async def download_segment(session, ts_url, true_url, output_dir, cnt):
global pbar
filename = os.path.join(output_dir, true_url)
try:
async with session.get(ts_url) as resp:
resp.raise_for_status()
with open(filename, 'wb') as f:
async for chunk in resp.content.iter_chunked(1024):
if chunk:
f.write(chunk)
logging.info(f"下载完成: {true_url}")
with pbar_lock:
pbar.update(1)
except Exception as e:
logging.error(f"第{cnt}次下载失败: {true_url}, 错误信息: {e}")
if cnt == 3:
logging.error(f"重试次数达到上限,跳过下载: {true_url}")
with open(f'{output_dir}.err', 'a', encoding='utf-8') as file:
file.write(ts_url + '\n')
if os.path.exists(filename):
os.remove(filename)
with pbar_lock:
pbar.update(1)
else:
await download_segment(session, ts_url, true_url, output_dir, cnt+1)
async def download_m3u8(m3u8_url, output_dir):
global pbar
logging_file = f'{output_dir}-download.log'
err_file = f'{output_dir}.err'
if os.path.exists(logging_file):
os.remove(logging_file)
if os.path.exists(err_file):
os.remove(err_file)
if os.path.exists(output_dir):
shutil.rmtree(output_dir)
logging.basicConfig(filename=logging_file, level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
os.mkdir(output_dir)
logging.info(f"开始解析 m3u8 文件: {m3u8_url}")
m3u8_obj = m3u8.load(m3u8_url)
base_url = re.split(r"[a-zA-Z0-9-_\.]+\.m3u8", m3u8_url)[0]
logging.info(f"提取到的base URL: {base_url}")
async with aiohttp.ClientSession() as session:
tasks = []
pbar = tqdm(total=len(m3u8_obj.segments))
logging.info(f"segment 个数: {len(m3u8_obj.segments)}")
for _, segment in enumerate(m3u8_obj.segments):
ts_url = base_url + segment.uri
task = asyncio.create_task(download_segment(session, ts_url, segment.uri, output_dir, 1))
tasks.append(task)
await asyncio.gather(*tasks)
pbar.close()
logging.info(f"下载完成")
m3u8_url = "http://.../playback.m3u8"
output_dir = "4-2-1-ppt"
asyncio.run(download_m3u8(m3u8_url, output_dir))
|
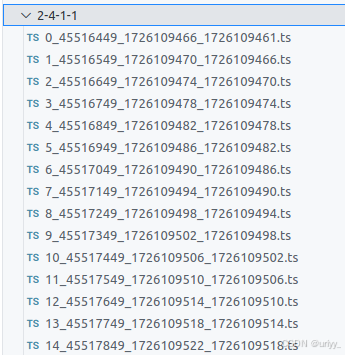
执行后会生成一个download.log,不过这个文件没啥用。主要还是ts文件夹,上述例子就会产生一个名为4-2-1-ppt的文件夹。
2. 合并为mp4
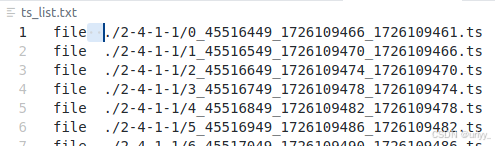
基于命令: ffmpeg -f concat -safe 0 -i ts_list.txt -c copy video.mp4。注意这个-i,如果只有少量文件,可以-i "concat:1.ts|2.ts|3.ts|4.ts|.5.ts|" ,但对于我们这种,就只能让他读取一个文件名列表文件,注意这个文件每行都是file+文件路径。
我代码里首先获取了ts文件夹里的所有ts文件名,但是因为多线程所以乱序,要先排个序才能让ffmpeg按顺序拼接。
实测1分钟左右合并完成。
如果看不懂代码,可以逐步运行查看效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import os
def main(dir_name):
filename = f'{dir_name}_ts_list.txt'
if os.path.exists(filename):
os.remove(filename)
f = open(filename, 'a', encoding='utf-8')
names = []
with os.scandir(dir_name) as entries:
for entry in entries:
if entry.is_file():
names.append(entry.name)
names.sort(key=lambda x: int(x.split('_')[0]))
for name in names:
f.write(f"file {os.path.join(dir_name,name)}\n")
f.close()
mp4_name = f"{dir_name}.mp4"
if os.path.exists(mp4_name):
os.remove(mp4_name)
cmd = rf'ffmpeg -f concat -safe 0 -i ./{filename} -c copy {mp4_name}'
os.system(cmd)
main("./4-2-1-ppt")
|
其他:处理少数下载失败的ts
其实就是比较m3u8里的所有ts文件名和本地已下载成功的ts文件,看哪些还没写,保存到{output_dir}-url.txt下,通过点击链接手动下载并保存到ts文件夹中。
注意由于下载链接已经包含鉴权信息,所以这个链接给谁都可以直接用,无需特定的会话。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import m3u8
import os
import re
def record(url,output_dir):
with open(f'{output_dir}-url.txt', 'a', encoding='utf-8') as file:
file.write(url + '\n')
def find_err(m3u8_url, output_dir):
m3u8_obj = m3u8.load(m3u8_url)
base_url = re.split(r"[a-zA-Z0-9-_\.]+\.m3u8", m3u8_url)[0]
done = set()
with os.scandir(output_dir) as entries:
for entry in entries:
if entry.is_file():
done.add(entry.name)
all = set()
for _, segment in enumerate(m3u8_obj.segments):
all.add(segment.uri)
not_done = all - done
tmp = list(not_done)
tmp.sort()
for i in tmp:
record(base_url+i,output_dir)
m3u8_url = "http://.../playback.m3u8"
output_dir = "4-2-1-ppt"
find_err(m3u8_url, output_dir)
|
其他
- 其实也可以直接用ffmpeg一次完成:
ffmpeg -i http://.../playback.m3u8 -c copy 2-4-1.mp4,只是似乎是串行依次下载ts,速度不快。
- 我也有搜到用IDM下载或者potplayer播放,学长/弟/姐/妹可以自行尝试。
- 关于ppt视频的忽略音频流,ffmpeg可以设置参数,我没看这个
- 关于字幕生成,免费方案是B站必剪支持15分钟内视频的字幕生成,可以在必剪里裁剪和生成,但是有点麻烦而且效果很差。其他方案请自行研究。
- 似乎也有直接可用的m3u8播放器,请自行研究。如 nilaoda/N_m3u8DL-CLI。