数据结构与算法之美笔记之位图、布隆过滤器
位图(BitMap)
我们有1千万个整数,整数的范围在1到1亿之间。如何快速查找某个整数是否在这1千万个整数中呢?
答:
除了散列表,我们还可以申请一个大小为1亿的布尔数组,$arr[i]=true$表示$i$在这1千万个整数内,
但是因为很多语言中的布尔类型是$1Byte$的,空间还是很大。实际上,为了表示$true$和$false$,我们可以用$1bit$就行了
如下图就表示用了$1Byte$的$8bit$去作为下标存值,存的是1、4、6三个值
Java中一个int类型占用4个字节32位,假如说现在有一亿的数据量,使用普通的存储模式需要:100000000*4/1024/1024 约为381.5M的存储;使用bitmap存储模式需要:100000000/8/1024/1024 约为11.9M 的存储,可以看到存储减少了一个量级。
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| true表示该值存在 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
但是,我们之前提到的范围是1到1亿,如果范围更大怎么办?我们真的需要开辟更大的数组范围吗
布隆过滤器
布隆过滤器就是为了解决上面这个问题,对位图这种数据结构的一种改进。
布隆过滤器使用了hash算法,对要保存的对象,用多个hash函数分别得到一组hash值,这里设为$h_{1}$、$h_{2}$、$h_{3}$…$h_{k}$,然后将$bitmap[h_{1}]$、$bitmap[h_{2}]$…$bitmap[h_{k}]$设为true
当我们要查找一个对象是否在bitmap中存在时,我们重新用多个hash函数分别得到hash值,然后查找$bitmap[h_{1}]$、$bitmap[h_{2}]$…$bitmap[h_{k}]$是否都为true
如下图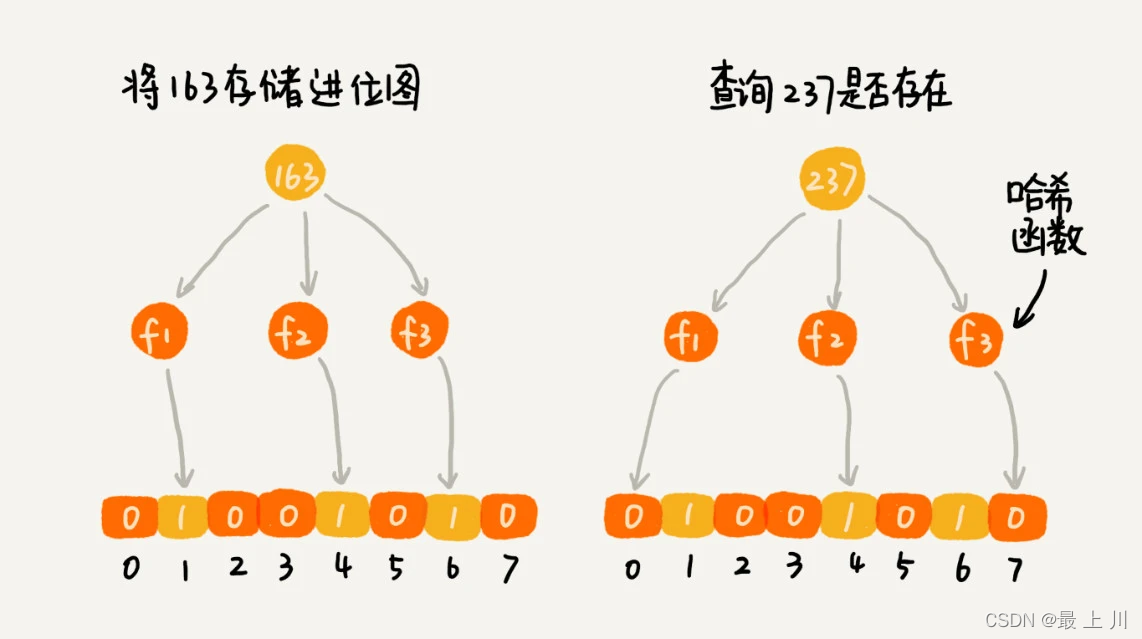
但我们也很容易想到,当保存的数越来越多,为true的位也越来越多,冲突的可能会越来越大,即容易误判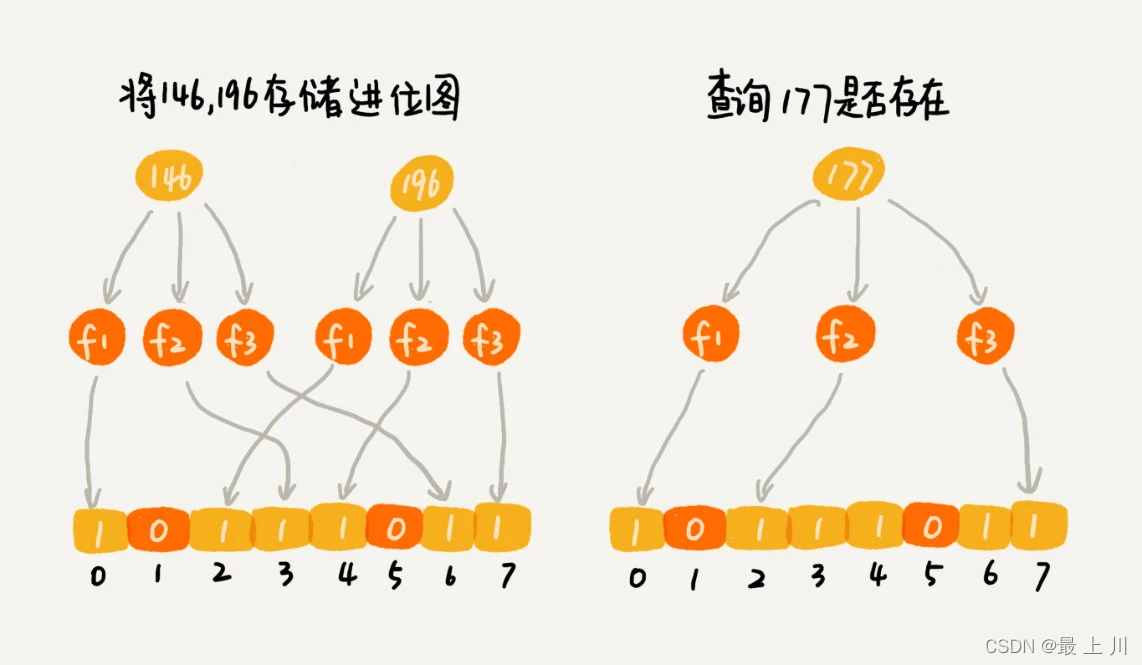
布隆过滤器的误判有一个特点,它只会对存在的情况有误判。如果某个数字经过布隆过滤器判断不存在,那说明这个数字真的不存在,不会发生误判;如果某个数字经过布隆过滤器判断存在,这个时候才会有可能误判,有可能并不存在。
不过,只要我们调整哈希函数的个数、位图大小跟要存储数字的个数之间的比例,那就可以将这种误判的概率降到非常低。
尽管布隆过滤器会存在误判,但是,这并不影响它发挥大作用。很多场景对误判有一定的容忍度。比如爬虫判重这个问题,即便一个没有被爬取过的网页,被误判为已经被爬取,对于搜索引擎来说,也并不是什么大事情,是可以容忍的,毕竟网页太多了,搜索引擎也不可能100%都爬取到。
在爬虫URL判重上,散列表和布隆过滤器的比较:
- 内存
我们用布隆过滤器来记录已经爬取过的网页链接,假设需要判重的网页有10亿,那我们可以用一个10倍大小的位图来存储,也就是100亿个二进制位,换算成字节,那就是大约1.2GB。之前我们用散列表判重,需要至少100GB的空间。相比来讲,布隆过滤器在存储空间的消耗上,降低了非常多。 - 时间效率
布隆过滤器用多个哈希函数对同一个网页链接进行处理,CPU只需要将网页链接从内存中读取一次,进行多次哈希计算,理论上讲这组操作是CPU密集型的。而在散列表的处理方式中,需要读取散列冲突拉链的多个网页链接,分别跟待判重的网页链接,进行字符串匹配。这个操作涉及很多内存数据的读取,所以是内存密集型的。我们知道CPU计算可能是要比内存访问更快速的,所以,理论上讲,布隆过滤器的判重方式,更加快速。
布隆过滤器的误判率,主要跟哈希函数的个数、位图的大小有关。当我们往布隆过滤器中不停地加入数据之后,位图中不是true的位置就越来越少了,误判率就越来越高了。所以,对于无法事先知道要判重的数据个数的情况,我们需要支持自动扩容的功能。
当布隆过滤器中,数据个数与位图大小的比例超过某个阈值的时候,我们就重新申请一个新的位图。后面来的新数据,会被放置到新的位图中。但是,如果我们要判断某个数据是否在布隆过滤器中已经存在,我们就需要查看多个位图,相应的执行效率就降低了一些。
- 标题: 数据结构与算法之美笔记之位图、布隆过滤器
- 作者: urlyy
- 创建于 : 2022-02-19 12:44:01
- 更新于 : 2025-12-21 18:39:57
- 链接: https://urlyy.github.io/2022/02/19/数据结构与算法之美笔记之位图、布隆过滤器/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。