scrapy个人循序渐进
- 学习动机
- 创建项目
- 第一个小demo
- 在Linux环境(虚拟机)下使用Docker配置NoSQL和MQ
- 获取请求中的数据
- 不遵守robots协议
- scrapy整合Playwright
- 代理池
- 规则化爬虫
- 数据存储
- 分布式爬虫
- 爬虫管理和部署
学习动机
我想写一个爬热点新闻的爬虫项目,最好能满足
- 规则化爬虫爬多个网站
- 结合docker和docker-copmpose和k8s进行分布式部署
- 具有代理池
- 充分使用Scrapy框架
- 可以结合一些NoSQL进行存储
- 作为一个服务方便调用(Flask)
创建项目
我是用conda创建的虚拟环境,这个自己去配去
创建环境conda create -n envName python=3.10
进入环境conda activate envName
安装scrapypip install scrapy
创建项目scrapy startproject newsCrawlernewsCrawler是我的项目名
跟着他的提示cd newsCrawlerscrapy genspider example example.com这个example是一个你的Spider类,他会作为example.py在spiders文件夹里,这个类设置的爬取的网站是example.com,这个可以自己再改的,所以无脑用就行
第一个小demo
爬取的是百度热搜
- 定义新闻数据实体,在items.py中
1
2
3
4
5
6import scrapy
class NewsItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
time = scrapy.Field() - 修改spiders文件夹内的
exampleSpider.py为baiduSpider.py,修改允许爬取的域名和起始URL1
2
3
4
5# 部分代码
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['top.baidu.com']
start_urls = ['https://top.baidu.com/board?tab=realtime'] - 分析网站结构,编写解析网站元素得到目标数据的爬虫代码
1
2
3
4
5
6
7
8# 这个代码和上面的是一块的,这个parse就是BaiduSpider的类方法
def parse(self, response):
news_list = response.xpath('//*[@id="sanRoot"]/main/div[2]/div/div[2]/div[position()>=1]')
for news in news_list:
item = NewsItem()
item['url'] = news.xpath('./div[2]/a/@href').get()
item['title'] = news.xpath('./div[2]/a/div[1]/text()').get()
yield item - 在
settings.py中配置以UTF-8导出,不然中文会以unicode字符显示。(似乎也可以在Spider中写编码或者用Pipeline中编码并导出,但我就是用的命令导出的,所以没考虑那两个)
这个配置随便找一行放上去即可,居左1
2# 导出数据时以UTF-8编码导出
FEED_EXPORT_ENCODING='UTF-8' - 编写启动类
其实我们这里是用python执行命令行代码,这样会方便很多
创建一个main.py1
2
3
4
5
6
7from scrapy.cmdline import execute
if __name__ == '__main__':
# 同在cmd中输入 scrapy crawl baidu -o baidu_news.json
# 注意第一个baidu是被执行的spider的name
# 如果不想打印日志,可以再加个'--nolog'
execute(['scrapy', 'crawl', 'baidu','-o','baidu_news.json'])
在Linux环境(虚拟机)下使用Docker配置NoSQL和MQ
获取请求中的数据
https://news.qq.com/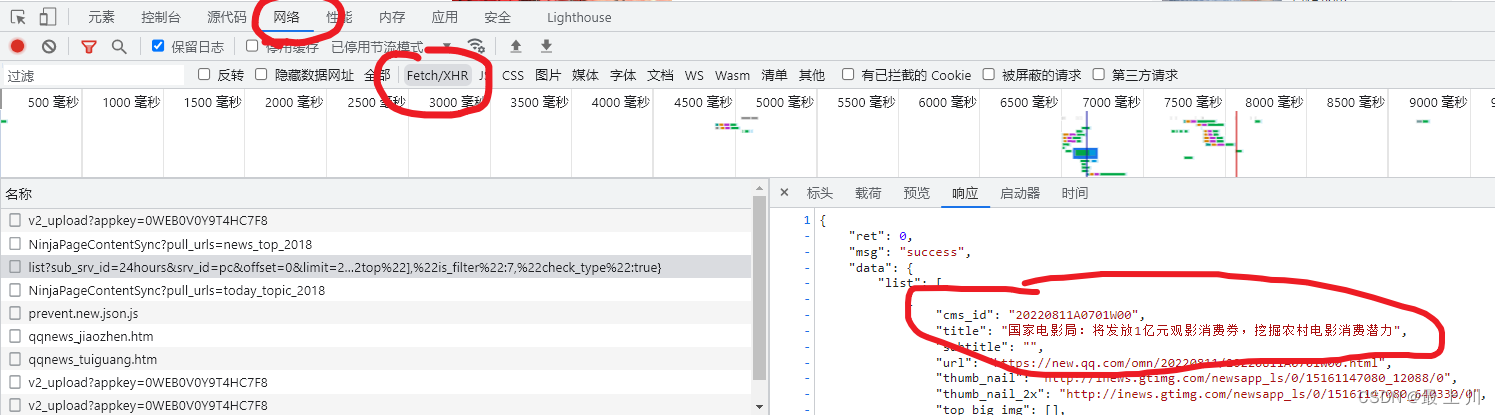
在控制台中发现数据是从接口中获得的
请求网址:https://i.news.qq.com/trpc.qqnews_web.kv_srv.kv_srv_http_proxy/list?sub_srv_id=24hours&srv_id=pc&offset=0&limit=20&strategy=1&ext={%22pool%22:[%22top%22],%22is_filter%22:7,%22check_type%22:true}
请求方法:GET
携带数据:
貌似没有加密参数,即没有采取反爬,于是不准备模拟浏览器,而是直接爬取请求
1 | import json |
不遵守robots协议
突然看到一个汇总了各个新闻网链接的网站http://www.hao123.com/newswangzhi
结果爬不动,发现robots协议是这样的:
1 | User-agent: Baiduspider |
意思就是除了上面这些,其他的都不能爬,所以要禁用robots协议
在settings.py中将该参数由True修改为False
1 | # Obey robots.txt rules |
这个的代码就不放了,没啥含金量
robots协议是让搜索引擎判断这个页面是否允许被抓取的,所以我们自己的爬虫练习还是可以把他关掉的
scrapy整合Playwright
https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=1
这个新浪的滚动网站
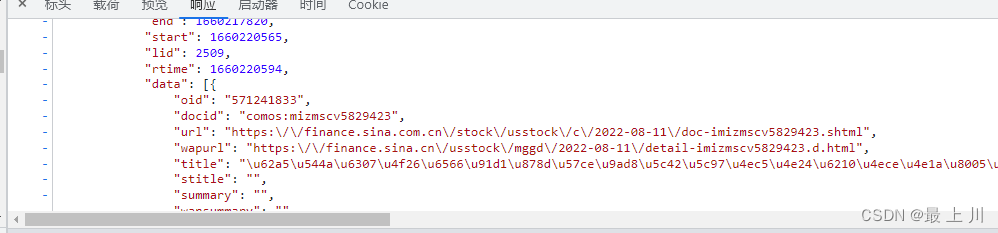
通过观察发现也是一个用接口获得数据的,其实这个从他每一分钟就异步刷新一次就知道
但是下面这三个参数发现是随时间变化的,因为还没到能逆向的程度,所以直接选用模拟浏览器的操作进行爬取,选用的是Playwright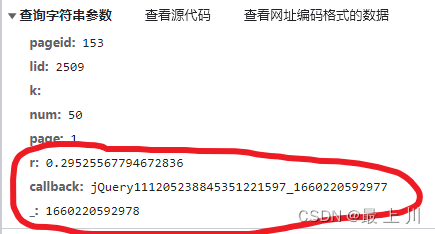
先写个demo
安装Playwright
注意第二行是为我们安装浏览器及驱动及配置
1 | pip3 install playwright |
不得不说这个网站也太离谱了,返回结果居然不是一个json,花了半天弄出格式化的json字符串切片
下面只是一段测试代码,未接入scrapy
1 | import json |
接入Scrapy
我们直接导入崔庆才大大的Gerapy Playwright的包,这个包整合了Scrapy和Playwright
三行代码,轻松实现 Scrapy 对接新兴爬虫神器 Playwright!
GIthub项目地址
但是会有多个问题

This package does not work on Windows,所以不能在windows上运行,会报NotImplementedError,我索性在虚拟机上安装了anaconda并运行项目,步骤如下:- 安装
官网链接
参考博客:centos7 安装Anaconda3 亲测成功
注意安装过程中这个路径是anaconda的文件夹路径,这里是我自己手动输入的 - 导出项目依赖
pip install pipreqspipreqs ./ --encoding utf-8 - 把项目发到虚拟机上,使用conda创建虚拟环境Conda 创建和删除虚拟环境 ,进入虚拟环境
pip install -r requirements.txt安装依赖,然后在虚拟环境下用命令行运行该Spider,然后进入第二个坑
- 安装
scrapy报错twisted.internet.error.ReactorAlreadyInstalledError: reactor already installed,报错见标题,方法见博客
出现gzip.BadGzipFile: Not a gzipped file (b’<!’) 的解决办法。这个似乎是崔大大没弄好,跟响应头里有gzip有关,观察发现确实这个响应是这样的
仓库Issues里有人给了解决方案:去掉一个中间件,即
然后项目就能起来了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import scrapy
from gerapy_playwright import PlaywrightRequest
from newsCrawler.items import NewsItem
class SinaSpider(scrapy.Spider):
name = 'sina'
allowed_domains = ['news.sina.com.cn']
base_url = 'https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=1'
def start_requests(self):
# 大佬的包,解决了爬取页面的问题
yield PlaywrightRequest(
self.base_url,
wait_until='domcontentloaded',
callback=self.parse,
# 注意这里要设个等待时间,等ajax数据显示在网页上
sleep=0.5
)
def parse(self, response):
# 第一层是一些ul
news_1_list = response.xpath('/html/body/div[1]/div[1]/div[2]/div[3]/div[2]/div/ul[position()>=1]')
for news_1 in news_1_list:
# 第二层是一些li
news_2_list = news_1.xpath('./li[position()>=1]')
print(len(news_2_list))
# 每个li都是一个新闻
for news in news_2_list:
item = NewsItem()
item['title'] = news.xpath('./span[2]/a/text()').get()
item['url'] = news.xpath('./span[2]/a/@href').get()
yield item



代理池
怎么说呢,崔大大讲的大部分思想都能看懂,但是代码就看不懂了。。。
所以直接拿来用了!
仓库地址
安装并运行过程:(Docker-Compose版)
- 准备好Docker和Docker-Compose Linux下Docker安装几种NoSQL和MQ和乱七八糟的
- 把项目down下来
git clone https://github.com/Python3WebSpider/ProxyPool.gitcd ProxyPool - 使用docker-compose运行
docker-compose up -d
注意这里可能会重试很多次,但是总还是会成功的,要等久一会,然后就是不断的命令行输出对代理的爬取、判活之类的消息了 - 尝试获取IP
http://IP:5555/random
仓库里也有个用requests获取代理池内代理的example,我都没想过这个。。。第一反应就是Flask,太傻了
规则化爬虫
这章的内容是真的多,一看吓死人,再一看稍微好一点
主要多了几个东西
ItemLoader
这个就是包装了你的自定义Item,同时它的子类可以灵活定义数据存入取出时的逻辑
拿爬宣讲家网举个涉及知识点较少、适合入门的例子:
NewsItem是一个Item我们进入详情页,注意是详情页!!!1
2
3
4
5class NewsItem(scrapy.Item):
title = scrapy.Field()
url = scrapy.Field()
# 新闻媒体
media = scrapy.Field()
观察发现我们需要的内容,即标题和媒体,他们都只出现一次,所以我们定义一下在该页面的读取规则,因为待会用xpath之类的选择器读取的时候不能用extract_first这类的东西了,只能写selector
定义一个为该Item定制的Loader1
2
3
4
5
6
7
8
9from scrapy.loader import ItemLoader
from itemloaders.processors import TakeFirst,Join,Compose
class NewsItemLoader(ItemLoader):
# 默认类中全部变量都只是该页面第一次匹配的结点的数据,且去除左右空格
default_output_processor = Compose(TakeFirst(),str.strip)
# 也可以如下
# title_out = Compose(TakeFirst(),str.strip)
# url_out = Compose(TakeFirst(), str.strip)- 首先这里能定义in和out,即数据从页面提取并放入loader和从loader拿出到item中的两个阶段都能进行处理,我这里只处理了out
- 然后发现这里似乎是通过后缀来判断的,即是否为_in还是_out
- 我的第一行是配置的item中全部变量的规则,我们其实可以在下面对某个变量重新赋予规则,覆盖这个全局规则的
- 常用规则是:不进行处理
Identity,匹配到的结果的第一个非空值TakeFirst,将结果通过某种分隔符拼接Join,组合多个函数Compose、处理jsonSelectJmes。还有一些东西可以看看关于Scrapy ItemLoader、MapCompose、Compose、input_processor与output_processor的一些理解
以上,进行完了详情页面的解析
CrawlSpider
这个类是Spider类的子类,你暂时可以理解他比Spider多了个rules元组,里面放了很多Rule对象,他们包含了在列表页面找到新闻链接和翻页按钮的规则、找到链接后爬取完详情页html后的回调函数等内容。就是说我们现在是在进行新闻列表的解析,即在列表页面获取想要的新闻的链接,因为我们是要通过这些链接获取详情页html的嘛
3.LinkExtractor
上面那个没代码是因为他的Rule对象的配置的规则实际上是配在这个类里的。这个类参数都是一些选择器、域名黑白名单、后缀黑名单等内容
注意一下CrawlSpider也是可以通过genspider进行生成的,他有几个模板,默认模板的其实就是我们之前用的那个。我们这次选择然后我们再稍微改下speaker.py1
scrapy genspider -t crawl speaker www.71.cn
运行可出结果,但是我大意了,有些详情页面结构不一样的,不过无伤大雅1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from newsCrawler.items import NewsItem
from newsCrawler.loaders import NewsItemLoader
class SpeakerSpider(CrawlSpider):
name = 'speaker'
allowed_domains = ['www.71.cn']
start_urls = ['http://www.71.cn/']
rules = (
Rule(LinkExtractor(restrict_xpaths='/html/body/div[8]/div[1]/div[2]/div[2]/div/ul/li[position()>=1]/a',attrs='href'), callback='parse_detail'),
# 因为只是简短demo我就没找有分页的网站了,分页就是如下,只会进行跳转而不会调用回调函数
# Rule(LinkExtractor(restrict_css='.next'))
)
def parse_detail(self, response):
# 包装item
loader = NewsItemLoader(item=NewsItem(),response=response)
loader.add_value('url',response.url)
loader.add_xpath('title','//*[@id="main"]/div/div[2]/div[1]/div[1]/h1/text()')
loader.add_xpath('media','//*[@id="main"]/div/div[2]/div[1]/div[1]/div[1]/span[2]/text()')
yield loader.load_item()
真正规则化
为啥上面弄了什么loader、Rule这些东西啊,仔细看下,他们把爬取列表上的链接、爬取结点的选择器、结点的in-out规则都分开了,且都是对象或字符串的形式,而不是用extract_first之类的方法进行操作,我们完全可以把他们放进配置文件里头啊!我们定义一个通用Spider,它会获取要调用哪个配置文件,再使用这些配置进行爬取,这样就可以大大提高项目的可维护性了
具体代码我就不写了,因为我项目暂时不太大,然后有些地方不是单纯用配置文件抽取变量就能解决的,比如scrapy-playwright那边,所以只留个思想在这吧
数据存储
这个只涉及ItemPipeline
我这里也只演示存储进redis
- 首先是安装redis,这里继续参考Linux下Docker安装几种NoSQL和MQ和乱七八糟的
- 安装redis包以便操作redis
1
pip3 install redis
- 在settings.py中配置参数
1
2
3
4
5
6
7
8REDIS_HOST = '192.168.192.129'
REDIS_PORT = 6379
REDIS_DB_INDEX = 0
REDIS_PASSWORD ="root"
ITEM_PIPELINES = {
'scrapyRedisDemo.pipelines.RedisPipeline': 300,
} - 编写pipeline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21from redis.client import StrictRedis
from redis.connection import ConnectionPool
class RedisPipeline(object):
def open_spider(self, spider):
# 第一个参数是settings.py里的属性,第二个参数是获取不到值的时候的替代值
host = spider.settings.get("REDIS_HOST")
port = spider.settings.get("REDIS_PORT")
db_index = spider.settings.get("REDIS_DB_INDEX")
db_psd = spider.settings.get("REDIS_PASSWORD")
# 连接数据库
pool = ConnectionPool(host=host, port=port, db=db_index, password=db_psd)
self.db_conn = StrictRedis(connection_pool=pool)
def process_item(self, item, spider):
self.db_conn.rpush("news", item['title'])
return item
def close_spider(self, spider):
# 关闭连接
self.db_conn.connection_pool.disconnect() - 检验是否放入
我是用redisinsight可视化工具查看的,但是好像图里有涉及国家政治方面的内容所以图挂了。不再贴了
分布式爬虫
这里使用的是scrapy-redis包。当然也可以用消息队列,但我没用。
其实单机scrapy就内置了一个队列存放Request,并由调度器拿取Request,同时他还内置了去重、中断时记录上下文等功能。
但是实现分布式的话,肯定不能用内置的这些队列和功能,这些逻辑应该放到分布式中间件上
Scrapy-Redis解析
首先内置了三种集合:队列、栈、有序集合
然后实现了去重,即将item的hash值作为指纹,同时指纹用set去重存储,每次存入item前先查看是否存入指纹成功,成功则存入item,否则不存入
然后也实现了中断时记录上下文
Scpray-Redis的demo
爬取的是4399最新小游戏
1 | #发现一个东西,记录一下 |
1 | # BT.py |
1 | # items.py |
重要的来了!!!!!配置Scrapy-Redis
settings.py中添加
1 | # Redis连接参数 |
自定义去重逻辑为布隆过滤器
这里就不详细讲布隆过滤器了,但还是简单提一句:
知道位图bitmap不?比如五个人,每个人有及格和不及格两种情况,就可以用一个五位二进制数,如01100表示第二个和第三个人及格了,但是每多一个人就要多加一位,相对费内存,在数据量大时不太好
于是有一种方法:指定多个哈希函数,对要存入的数进行哈希,然后把每个哈希值对应的位的值变为1,这样容易冲突、误判,但是确实降低了内存消耗,而且原则是能查到的可能是误判,但是查不到的一定不存在
直接用了崔大大的包了
1 | pip install scrapy-redis-bloomfilter |
然后在settings.py中增加或修改如下配置
1 | DUPEFILTER_CLASS = 'scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter' |
此时发现redis中的指纹集合的后缀就是bloomfilter了
爬虫管理和部署
多机同时更新改动肯定是很麻烦的事,所以我们需要一个管理平台
基于Scrapyd(别看,乱写的,直接学Docker的)
提供了管理各Scrapy项目的命令
Scrapyd -Client
1 | pip3 install scrapyd-cient |
相比于单纯的Scrapyd提供了一系列更方便的API
然后我们就要对项目进行一些配置的修改了
对于项目里的scrapy.cfg,修改url为被部署的主机的url,让scrapyd能访问到,同时为该主机起个别名spyder-2
1 | [deploy:spyder-1] |
在项目里执行scrapyd-deploy vm-1 部署
可视化管理Gerapy
看到Gerapy我就知道崔大大又来推广自己的项目了(笑
这是一个基于Scrapyd、Django、Vue.js的分布式爬虫管理框架,提供图形化管理服务
- 安装
pip3 install gerapy - 初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19在当前目录生成gerapy文件夹
gerapy init
初始化数据库
gerapy migrate
生成管理员账号
gerapy initadmin
默认在8000端口上启动服务
gerapy runserver
3. 在服务器上进行访问,不知道为什么我不能远程访问这个网页。。。
`http://localhost:8000`
4. 登录 账号密码都是`admin`
5. 添加主机的Scrapyd运行地址和端口,并在gerapy/project目录下存放Scrapy项目,Gerapy支持项目可视化编辑、可视化部署、启停、日志等服务
。。。。。。。。。。。。。。。。。。。。。我反正没搞懂咋弄的,直接学Docker+K8S的算了,通用一些。。。。。。。。。。。。。。。。。。。。。
# 基于Docker
## 使用Docker
1. 在项目根目录导出项目依赖
```shell
pip install pipreqs
pipreqs ./ --encoding utf-8 - 在项目根目录编写Dockerfile文件
1
2
3
4
5
6
7
8
9
10
11
12使用了Docker基础镜像之python3.10
FROM python:3.10
指定工作目录
WORKDIR /spyder
把依赖文件复制到工作目录下,即/spyder
COPY requirements.txt .
安装包
RUN pip install -r requirements.txt
这里是故意把整个项目的复制放到后面的,具体原因太长了我就不写了
COPY . .
容器启动时执行的命令
CMD ["scrapy","crawl","4399"] - 修改配置项,让settings.py中的配置是从环境变量中获得
1
2# REDIS_URL = 'redis://user:pass@hostname:9001'
REDIS_URL = os.getenv('REDIS_URL') - 进入项目根目录打包镜像,注意最右边是个点,表示当前目录。注意项目名必须全小写,不然报错
invalid reference format: repository name must be lowercase用1
docker build -t 项目名 .
docker images查看镜像是否创建成功 - 指定环境变量
在部署的服务器上找个位置创建一个.env文件,针对你settings.py中的环境变量编写,比如我的就是注意不要有空格出现1
REDIS_URL='redis://:root@host.docker.internal:6379'
- 在.env的目录下运行
1
docker run --env-file .env 镜像名
- 推送至docker hub
在官网注册再登录,注意username是跟你以后仓库地址有关的,比如仓库名叫demo,username叫lyy,那么仓库地址就是lyy/demo
用docker login命令也可以登录
给本地镜像打标签推送镜像到Docker Hub1
docker tag 镜像名:版本 想放的仓库地址:版本
1
docker push 想放的仓库地址:版本
- 以后运行这个镜像
只需要
创建一个 .env
然后1
docker run --env-file .env 镜像名
使用Docker Compose(更方便)
这是一个用yaml配置服务的工具,比Docker命令方便多了
- 编写
docker-compose.yaml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16version: "3"
services:
redis:
# 使用已有的镜像进行构建
image: redis:alpine
container_name: redis
ports:
- "6379"
scrapyRedisDemo:
build: "."
image: "truedude/scrapyredisdemo"
environment:
REDIS_URL: 'redis://:root@192.168.192.129:6379'
# 等redis起了才起这个容器
depends_on:
- redis - 打包为镜像
1
docker-compose build
- 运行镜像
1
docker-compose up
- 推送镜像
1
docker-compose push
K8S的使用
TODO
- 标题: scrapy个人循序渐进
- 作者: urlyy
- 创建于 : 2022-08-14 12:55:02
- 更新于 : 2025-12-21 18:39:57
- 链接: https://urlyy.github.io/2022/08/14/scrapy个人循序渐进/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。