Lightfm学习记录
推荐参考资料
上面的引用资料都很有用!
一些使用的细节
对于用户和物品的特征设置权重
注意网上的文章大多都是未设置权重的,如(user id, [list of feature names]),但是从官方文档我们可以看到实际上是可以设置权重的(user id, {feature name: feature weight})
这个权重的意思就是某字段在全部字段中的占比,比如
打印稀疏矩阵
一般的交互矩阵都是稀疏矩阵,貌似没有很好的实现__str__,为了查看矩阵的值,参考下方
1 | (interactions, weights) = dataset1.build_interactions([(x[0], x[1], x[2]) for x in df.values ]) |
矩阵分解
日常业务中可以得到用户的行为数据(交互),如点赞/评分等,如三元组{userID,itemID,rate},但是复杂业务中矩阵会很大,且矩阵十分稀疏(可能1w个物品,用户A只点赞了5个,我们在lightfm中使用的就是scipy的coo_matrix和csr_matrix)。我们的推荐,实际上就是预测这些空白项的值。因此我们引入矩阵分解,将这个大矩阵分解为两个较小的矩阵以实现降维,如M x N分解为M x k和k x N,即把他们投射到k维(这个k无法解释,此时就成为隐向量了)。此时两个小矩阵重新一乘,原来有的项会近似相等,原来的空白项此时也有值,那么这些值就是预测值了。
而对于这个分解过程,就有一些算法和目标函数了,我暂时还没搞懂
按照论文的说法,至少比MF模型和CB要好
混合模型
由于协同过滤需要历史交互数据,存在冷启动问题;同时由于基于内容的推荐没有使用交互,用户之间是孤立的,所以实际效果不如协同过滤。所以提出了混合模型,结合了基于内容的推荐(CB)和协同过滤的基于模型推荐(CF协同过滤,MF矩阵分解)两种方式,训练者可以传入用户/物品的特征信息(如地理位置/年龄)等,同时也传入交互信息{userID,itemID,rate},那么在数据少时仍可以基于用户物品的特征进行适当的推荐
所以,如果没有传入用户物品的特征信息,那么模型只是一个单纯的MF模型,基于内容是通过embedding实现的
而embedding是通过矩阵分解?得到的,事实上M x k的矩阵元素都是embedding
论文解读(我是科研新人,如有不对欢迎指正)
模型的需求:1. 如果物品A和B经常同时被推荐,那么应该学到A和B非常相似 2. 模型能即时根据新数据进行更新
对于需求一,使用latent representation,根据交互信息确定两个物体的embedding的距离。
对于需求二,将用户和物体表示为内容特征的线性组合
对于predict,就是是对用户/物品的已分解出的特征矩阵进行点积,再加上偏置,得到一个值$\hat r_{ui}$,这个就是MF模型的方法。但是这个$q_u$和$p_i$还有那两个偏置都是各特征之和(也算线性组合),所以也融入了一点CB的思想。
$$
\hat r_{ui} = f (q_u · p_i + b_u + b_i)
$$
目标函数是求最优化的分解出的矩阵,利用了交互信息,即对于交互信息(有正向和负向的交互),每个{user,item}对求出$\hat r_{ui}$然后根据正负属性进行操作,累乘后再两部分相乘。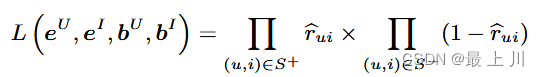
论文中提及的模型结构如下


我的demo
只是对于官方例子和参考其他人的例子改出来的demo,不知道是不是符合原作者的想法。
使用这个框架时,对于用户/物品的特征和交互量的量化,似乎也是一个关键,而所有例子都没有体现(包括我这个)。不过这本来也该是自己完成的。
1 | import pandas as pd |
- 标题: Lightfm学习记录
- 作者: urlyy
- 创建于 : 2024-04-05 16:00:38
- 更新于 : 2025-12-21 18:39:57
- 链接: https://urlyy.github.io/2024/04/05/Lightfm学习记录/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。