2024字节青训营笔记-Golang性能优化与GC
性能优化
原则
- 性能用实际数据衡量(benchmark、pprof),而不是理论估测。性能数据驱动、指导优化。
- 定位最大瓶颈而不是细枝末节。参考木桶效应。
- 不要过早优化。在实际业务中代码是不断迭代的,在前期就进行优化,开发成员需要理解并兼容这个优化,会影响项目在整个前中后期的开发进度。更别提万一需求变动大,这个优化不能兼容,反而需要被删掉的情况了。
- 不要过度优化。越高级的优化越容易出问题,代码反而不可靠了。
- 性能优化也要尽量保证代码的清晰可读。
分析工具
go-pprof-practice:仓库地址
这个项目提前埋入了一些炸弹代码,产生可观测的性能问题。会使用超过一个G的内存。
pprof是标准库中的一员,直接导入非常方便。他的使用方法就是开一个协程启动一个端口服务,可以在浏览器通过这个端口进入操作界面。注意对于"net/http/pprof"的import是用的_,即不会显式主动使用它,它会与net/http合作,自动注册到http的server上的。
1 | import( |
具体的使用,参考
在代码层面做性能优化
如果知道数组最大需要多大,建议在初始化时直接分配这么多内存,即
make(数组, 0, maxSize)。因为底层其实还是一个数组,然后保存了当前的长度与当前的最大容量。虽然append会动态扩容,但其实在大小超过当前最大容量时,是会申请一个更大容量的新数组然后将原来的数据拷过去,再将当前数据再append进这个新数组。(相信学过java集合源码的同学都懂这个)。所以预先设定容量,就可以避免这种新数组内存的申请与数据拷贝。map同理。1
2
3
4
5type slice struct
array unsafe.Pointer
len int
cap int
}
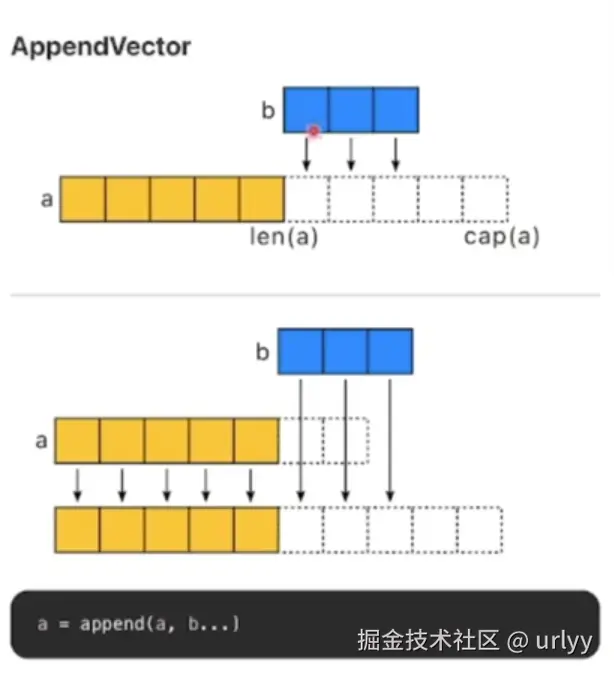
对于在大数组中选一段切片,建议使用
copy而不是re-slice。因为re-slice会给这个大数组添加一个引用,在感观上会延长这个大数组的生命周期。由于大数组会占用大内存,大数组的存活时间过长会影响我们的程序性能。
1 | // bad |
在频繁的字符串拼接上,善用
strings.Builder和bytes.Buffer。因为字符串是不可变量,用+直接拼接会分配一个大小为两个数组大小之和的新内存,然后将两个str依次拷进去。如果多次拼接会分配多次,性能较差。Builder和Buffer底层都是[]byte,而且有扩容策略(与前面讲的数组&切片一样),所以不会每次都重新申请内存,只会到达最大容量再重新申请,性能会好一些。关于Buffer和Builder的区别,Buffer会申请一个新内存,再将自己的[]byte转为string再返回。而Builder直接返回[]byte转成的string,可以理解为用的还是
同一个地址的数据。因此Builder性能会好一点,但是在某些特定场景应该不得不用Buffer。//To build strings more efficiently,see the strings.Builder type. func (b *Buffer)String()string if b ==nil //Special case,useful in debugging. return "<nil>" } return string(b.buf[b.off:]) } // String returns the accumulated string. func (b *Builder)String()string{ return *(*string)(unsafe.Pointer(&b.buf)) }进一步的,通过
builder.Grow(size)和buffer.Grow(size),我们可以设定那个底层[]byte的最大容量,传入所有字符串的长度之和,可以进一步减少内存申请。空结构体。这个只算一个常用trick吧,因为空struct不占内存,可以用
map[key_type]struct{}作为set来使用。视频里说他是一个优化手段是相较于拿bool当value_type而言,这种在value位置还是多占了一个byte。能用atomic就不要用lock。锁肯定是越小越好;然后atomic通过硬件实现,而锁是os实现。相比之下atomic性能好些。
性能调优案例

GC
栈内存要求数据大小是不变的,因此对于复杂对象,我们需要将他们本体在堆内存上申请内存,并将指针放在栈内存上。这就是动态分配内存。
在c和cpp中,堆内存需要程序员自行管理(这里不考虑RAII),对于大型项目,难免有疏漏,导致内存泄漏(忘记回收内存)、多次回收、悬空指针问题。为了减少程序员的心智负担,让程序员专注业务逻辑(以及减少企业损失),就有了垃圾回收(GC)的概念。
内存管理的任务:
- 分配内存
- 跟踪存活对象
- 回收死亡对象
GC的一些名词:
- Mutator:就是执行业务逻辑的程序使用的线程
- Collector:GC线程
- Serial GC:串行,其实就是只有一个GC线程
- Parallel GC:多个并行的GC线程
- Concurrent GC:Mutator和GC线程们同时执行
Concurrent GC单独提出来是因为它比较高级,因为运行中的业务程序中的对象们是在动态变化的,比起将动态的它们一一跟踪,让它们静止一秒然后GC扫一遍做处理再让它们动,后者明显简单很多,当然性能还是差一些。
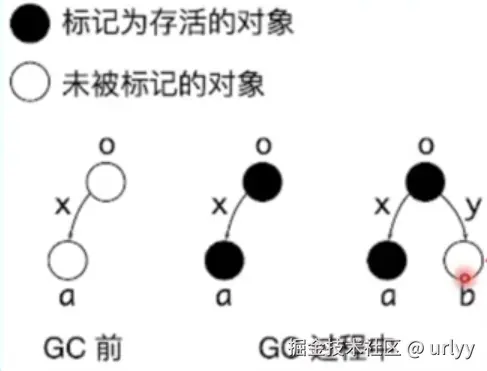
下图是Concurrent GC的挑战,如果在GC前,两个父子对象已经被标记为死亡但还未被回收,在GC启动后刚准备回收时,第三个对象引用了这个父对象,那么父对象就不该被回收,同时子对象引用了父对象,也不该被回收。GC就要应对这种即时的”死而复生”的情况,还要将依赖链中的所有对象重新标记为存活。
下图是对GC算法的评估标准。

JVM(也是golang)的GC策略
下图是对垃圾回收策略的解释。垃圾回收需要标记根对象、通过传递闭包标记存活对象,其他的不可达对象便是需要回收的。注意这可以理解为一种树状的搜索算法,对象只会是“可达”和“不可达”。
清理不可达对象的策略有三种
将内存分为两块,一块就是我们正常用的,另一块专门用于放
存活对象。我们将存活对象移出正常使用的内存,那么剩下的内存(包括不可达对象的内存)全都可以用于接下来的申请。优点是分配内存比较方便,缺点是内存拷贝开销大,而且需要专门开辟一块空间放存活对象。用一个free-list链表管理空闲内存块,回收就是把这个内存块插入链表中,而申请内存只需要在这个链表上找就行。优点是不需要拷贝,缺点是申请内存需要遍历链表,比较麻烦。
定期将存活对象移动到内存一侧(可以类比清除内存碎片),之后的申请直接在这块内存之后申请就行。这个主要是对标第一种,优点是不需要隔出两个内存空间,而且分配内存容易,缺点是需要将所有的都移动到内存一侧,开销大。

每种策略都有不同的优缺点。众所周知软件工程没有银弹,图片里也说了,会根据对象的特点做不同的标记和清理方式。
对于对象的区分,提出了“年龄”这个说法。对象的年龄与它们经过GC的次数有关,就是上面那三个策略,每次执行就会让存活对象年龄+1。
由于我们无法预知对象什么时候死亡,我们只能根据当前的年龄对他们进行判断。对于年龄大的老年代,经历多次GC仍然存活,并可能将继续长期存活,不适合用于开销大的内存拷贝,我们考虑用mark-sweep,只需要基于链表标记就行。
而年轻代对象,我们假定认为他们不会活太久,并且太老的一批已经是老年代了,我们认为现在的年轻代数量是少的,因此可以接受用copying管理。
通过对不同类型的对象进行不同策略的管理,能实现时空性能开销的折中。

引用计数
这个和JVM GC策略在一个层级,说明他也是一种GC策略,但因为缺点较严重不被Java使用。
策略就是为每个对象维护一个计数器,如果有其他对象引用了它,那计数器+1,如果计数器为0说明可以删除它了。它与JVM GC策略的区别就是在标记存活死亡对象上,它是”计数器==0”和”计数器>0”两种,而jvm的是”是否可达”两种。
看起来思想差不多,细节却天差地别。引用计数将计数操作与程序运行融为一体,似乎是更轻量了,但问题更多了:
对比JVM的树上搜索,引用计数无法找到与根节点分离的环状孤岛,而环状孤岛的每个又正好满足引用计数的存活标准:计数器>0。
对于计数器,其实是个AtomicInt,性能开销也不小。
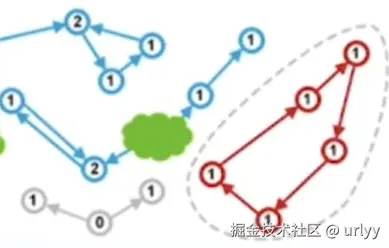
第一个缺点可以说是一个致命的缺点,导致它并没有被更多采用。
在SDK层面主动做性能优化
这里对应视频中的字节自研的GC。golang sdk的gc提前将内存分为特定大小的小块用于存储对象,并且有个多级缓存,将可以分配的内存放到离SDK近的位置,分配内存后逐级更新。
字节团队通过发现上线项目的内存分配特点:
- 对象分配是高频的,GB级别分配/s
- 小对象占比高
- 分配路径长(就是这个多级缓存)
然后提出的新方案Balanced GC是(我大致理解为):每个G作为一个可分配块,直接在上面用双指针移动来做内存分配,并且为了防止某个G上只有一个对象却导致这个G一直不释放,还用copying将这个对象移出去。
只是视频里没提到回收内存后这个G上的指针是怎么个情况,就说了个双指针,我感觉也是个free-list?
编译器为我们做的性能优化
在优化这块主要还是编译器后端部分,对于IP做优化。
编译器将代码文本树化之后,可以获得cg(调用图)、cfg(控制流图)、数据流图等。
我大概理解“过程”是指在一个函数内执行。如果只在一个函数内,只要看数据流就行了,跨越多个函数还需要结合上面导出的多个图,结合函数调用情况、参数传递情况等做分析,是个更复杂的问题。

因此,编译器有个inline函数内联,这个在cpp代码中常常显式出现,其实就是把函数定义直接拼到调用者这边,比如下面这样。
1 | func sum(a, b int) int { |
inline就可以让过程间变成过程内,简化问题,且更方便优化。但一个函数重复地在多处展开,其实也会增加最后编译产出的大小和编译时间。所以编译器也要根据被内联函数的大小,选择性的进行内联。
除此之外,逃逸分析也是个很重要的分析,即分析一个对象的生命周期是否被扩展,更像人话一点就是一个函数内的指针有没有赋给全局变量、有没有传到另一个函数内、有没有发到另一个goroutine里,这就是逃逸了。
逃逸也会增加分析和优化的复杂度,而刚刚的inline其实也会帮助对逃逸的分析和优化。
对此,视频也提到了字节自研的beast mode,其针对go编译器对于inline的策略过于保守的问题,通过调整策略增加了内联的程度,有利于逃逸分析,也为其他优化提供了更好的机会。同时还对不会逃逸的对象,改为在栈上分配内存,在不破坏程序安全的情况下,基于栈上快速的分配回收速度以及减少GC的负担,提高了程序性能。
- 标题: 2024字节青训营笔记-Golang性能优化与GC
- 作者: urlyy
- 创建于 : 2024-11-13 22:46:41
- 更新于 : 2025-12-21 18:39:57
- 链接: https://urlyy.github.io/2024/11/13/2024字节青训营笔记-Golang性能优化与GC/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。