2024字节青训营笔记-消息队列与定时任务
概览
消息队列是一个独立于业务项目的中间件容器,支持存储生产者的消息和允许消费者拉取消息。支持高吞吐、高并发、高可用。
消息队列作用:
- 解耦:将不同的服务通过消息队列关联,将各服务解耦。单个服务的崩溃不会影响整个系统的正常运行。
- 削峰:将突增的请求通过消息队列缓存,保证业务服务的可用。
- 异步:通过对耗时任务的延时执行和立即返回临时响应结果如”任务已提交”,保证响应速度,并实现数据的最终一致性。
- 日志保存:将耗时的日志操作交给消息队列异步处理。
主要项目:Kafka、RocketMQ、Pulsar、BMQ。其中RocketMQ更适用于实时业务场景(电商秒杀),Kafka适用于高吞吐场景(大数据处理)。
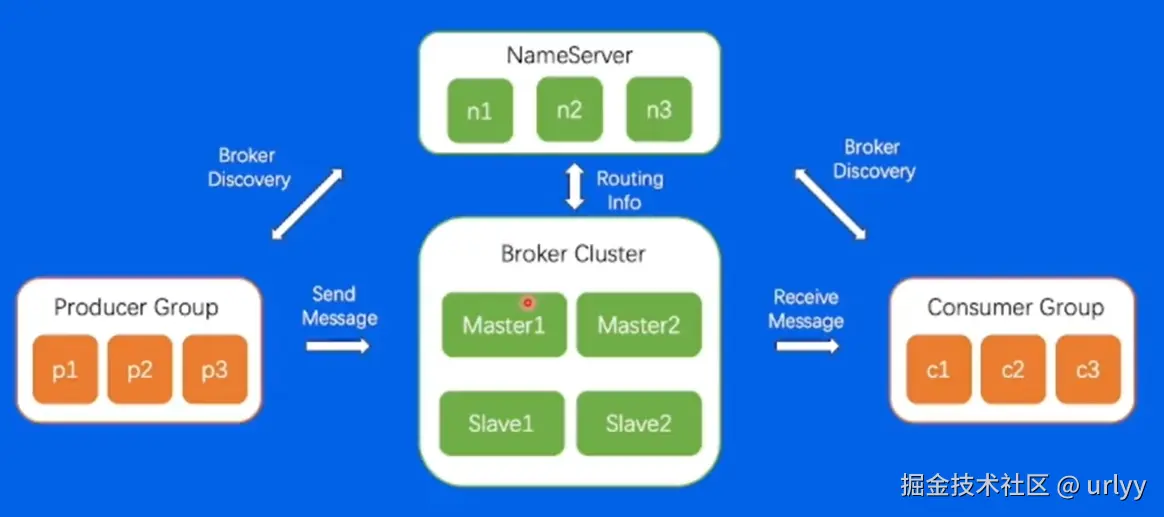
Kafka
Producer和Consumer为生产消息和拉取消息的业务服务。
Broker为存放消息的服务。一个Cluster中可以有多个Broker。
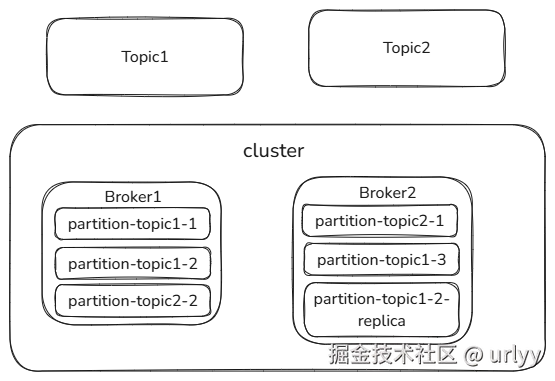
整个消息队列集群服务(多个Broker),有多个Topic(可以存放多种消息,只是一个逻辑上的分类)。
一个Topic中实际存放消息是在Partition中,每个Topic可以有多个Partition放在不同的Broker上,以实现对一个Topic读写时的分布式处理。
为了保证数据可靠,每个Partition可以有多个Replica(数据备份),这些Replica也可以在不同的Broker上。
对于Consumer可以设立Consumer Group,指定这组Consumer都是消费某个Topic的数据,可以结合负载均衡。
注意Kafka不支持Producer Group。
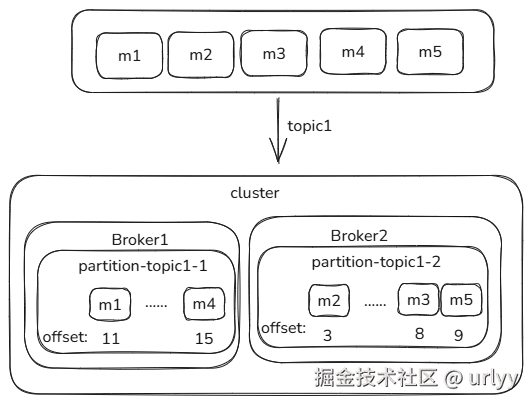
即:对于生产者发送的一组同一个Topic的消息,消息会被保存在不同的Broker上的属于这个Topic的某个Partition中,并且会在某个Broker上有一个Replica存了这个消息。每个Partition单独生成维护offset和消息的序号(在该partition内唯一且严格递增),而不是用生产者发送时的序号。所以虽然消息是顺序发送,但是如果某几个消息分在同一个Partition中还可以保持相对顺序,不同Partition中就无法查看相对顺序了。
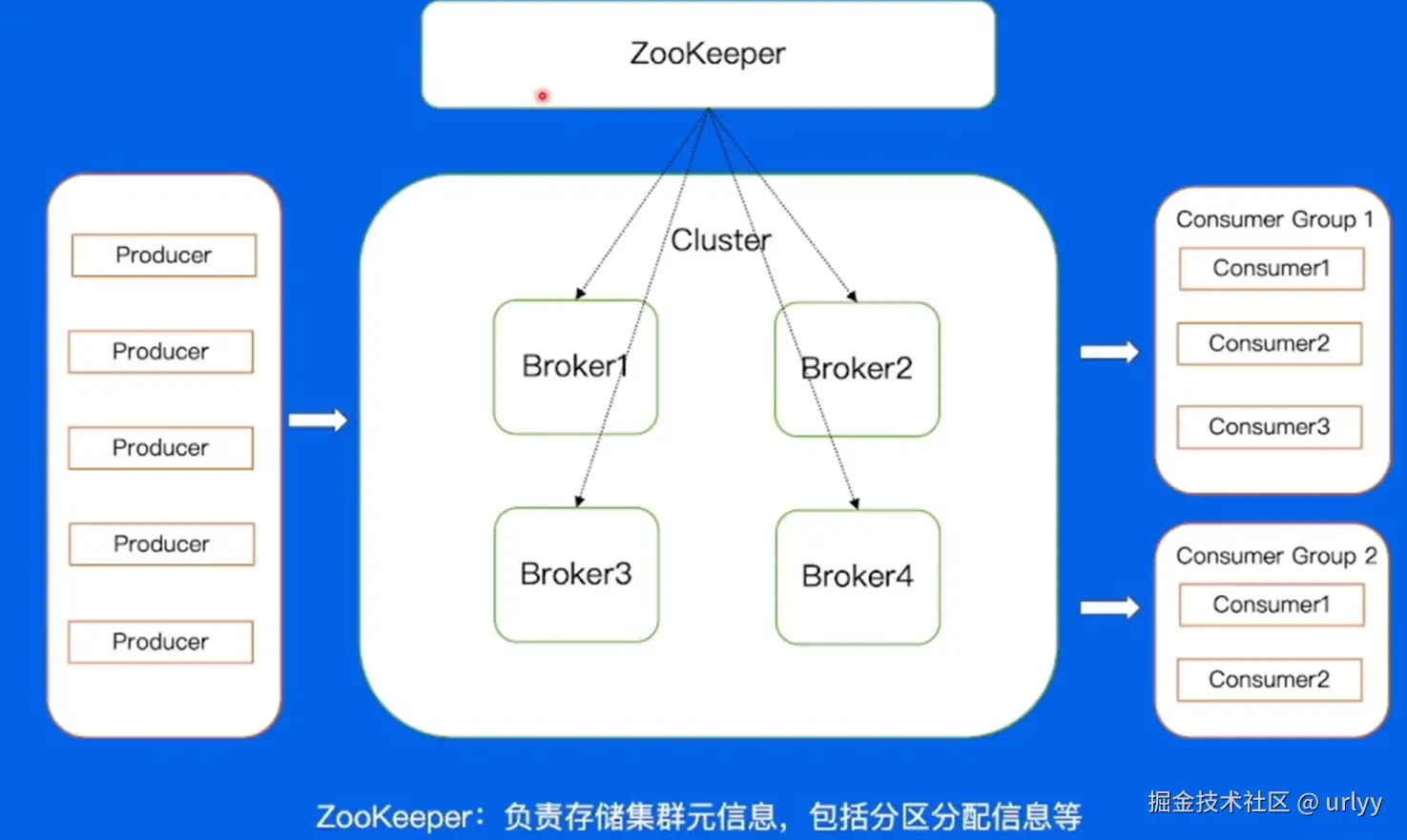
除此之外,整个集群有个Broker兼具Controller的角色,负责管理Broker、Partition和Replica的状态和关系。每个集群同时只能有一个Controller。
对于每个Partition中的多个Replica,分为主从,读写时只向Leader Replica,而Follwer是不断同步Leader的数据,以便在Follwer所在的节点(Replica可以分布在不同Broker、不同机器上)故障时,替代Leader继续承接业务。当一个Partition的Leader故障时,Controller就会发起选举,从该Partition中的所有Followr中选举出一个新的Leader。
在Cluster之上还有个ZK进行元数据管理。
消息队列可以做的优化
- 消息数量多时,Producer将多条消息批量发送,减少网络IO次数。同时为了防止这批消息太大而带宽不够用,进行数据压缩。
- Broker保存数据使用顺序写减少磁盘寻道时间。
- 由于顺序写保证日志文件有序,Broker使用二分查找目标文件。
- Broker使用零拷贝减少内存拷贝。
- 动态分配每个consumer处理哪个partition。便于进行结点的调整以及消息处理的负载均衡。
消息队列会存在的问题
replica中新增一个follower后,该replica需要花很长时间、很大的带宽追赶leader的进度。
partition的分配依赖手动分配,像下图的情况本应该将Partition3放在右边的Broker中,为Partition1预留足够空间。

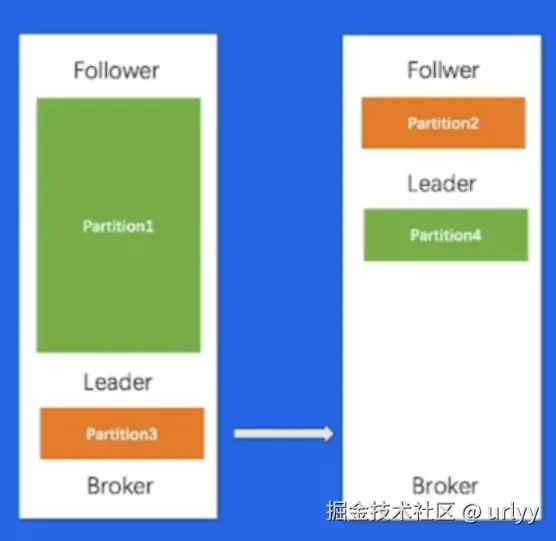
kafka存在的问题

RocketMQ
相比较Kafka有Tag、Producer Group、事务消息。
- 命名区别。kafka的Partition变成了ConsumerQueue;Controller变为Nameserver。
- Tag。可以在一个Partition中为每个msg打tag,比如一个order-topic,里面可能有create、pay、cancel多种tag,可以指定某个consumer只处理这个topic中的指定tag的消息。
- Producer Group。不同的Producer可能会交替发送,导致到同一个topic上的消息不能维持相对顺序。将一组Producer分为一组,可以保证他们发送的消息能保证相对顺序,便于后续的事务消息。
- 在数据备份中,Kafka是每个Partition内的多个Replica分主从,RocketMQ是在机器(Broker)上分主从。
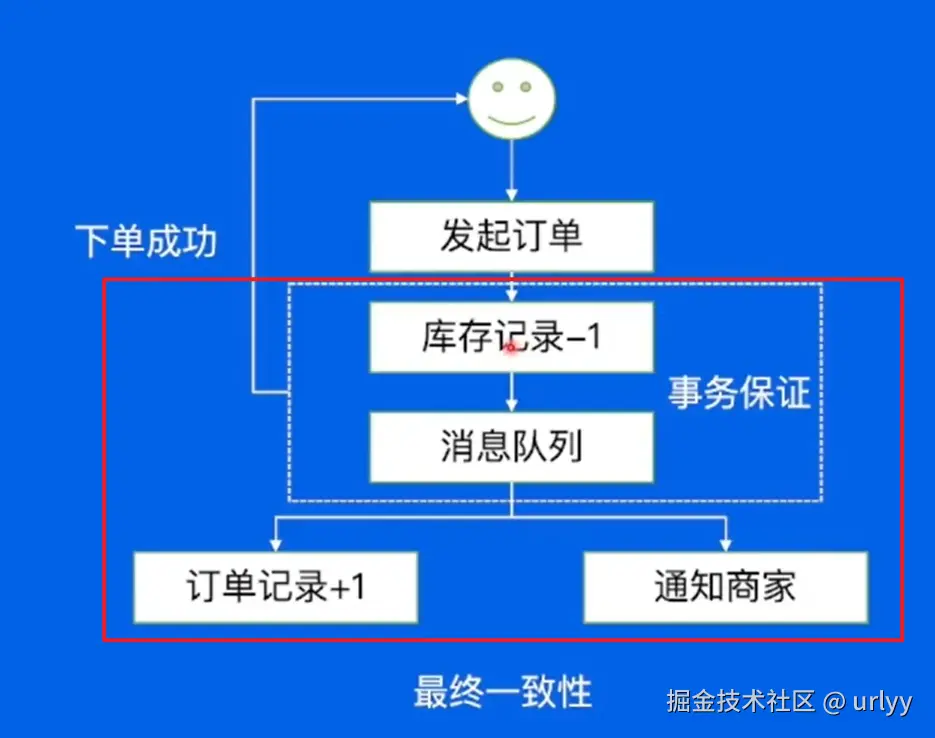
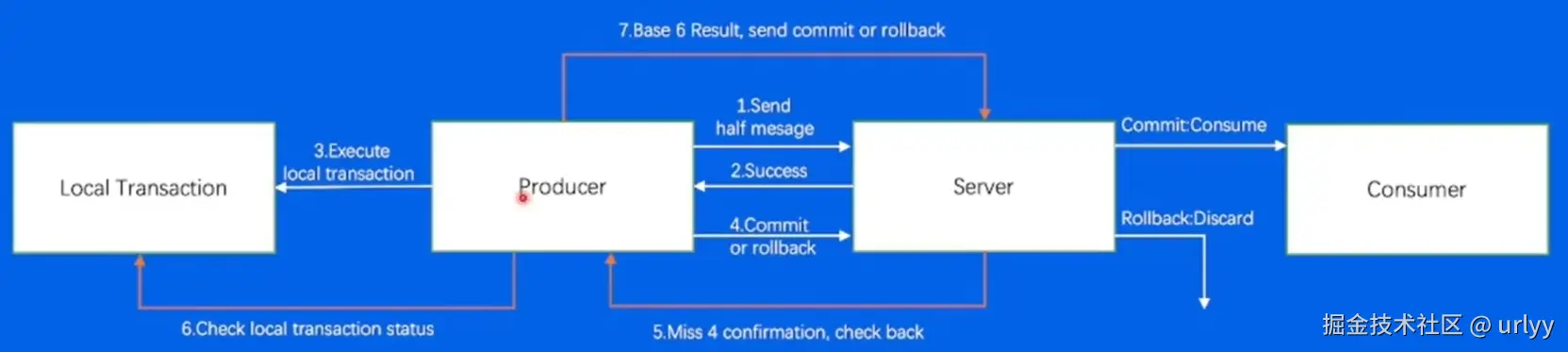
- 事务消息。保证库存-1和订单生成是原子的,不能扣了库存但是不生成订单。
本质上是两阶段提交。先告诉Broker我要提交了(让他等着接下来的Confirm消息),然后在Producer这边库存-1(本地事务),再通知Broker可以发送这个消息给consumer了。异常情况就是Broker意外没收到Producer的通知,就会主动通知Producer重发下本地事务处理结果。这样就保证了本地事务和消息处理是在一个分布式事务中。 - 延迟发送。RocketMQ有一个专门的ScheduleQueue存延时消息,并用一个线程监听哪些任务到时间了。到时间了的任务就会把他们重新写一个log,然后作为正常消息放入queue中等待消费。
- 消费失败处理。对于消费失败的数据,会放到一个RetryQueue中,允许Consumer再次拉取这条消息进行重新消费。如果超过一定重试次数,就会把这条消息放入死信队列中,交由平台管理员手动检查和处理。
分布式定时任务
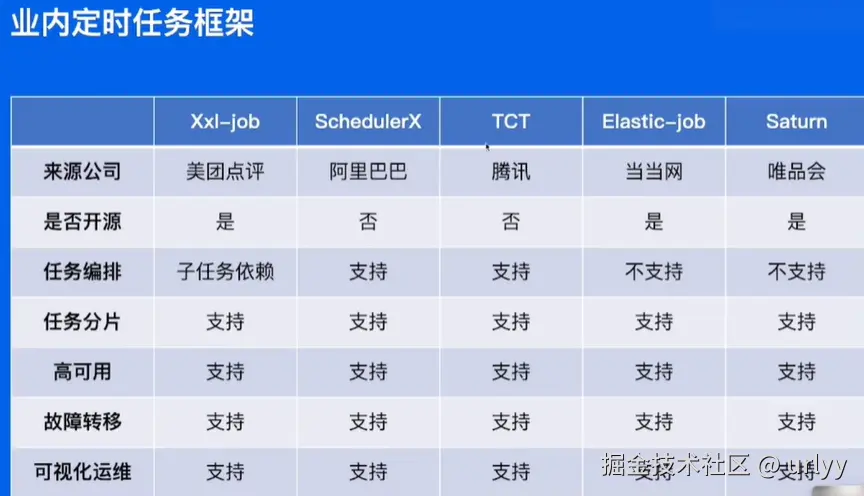
分布式系统中,对于整体的定时任务,需要一个统一的定时任务管理平台。Quartz只能实现单机的任务调度。
定时任务的类别:
- 延时:一段时间后触发(五分钟后触发)。
- 定时:特定时间触发(每天零点、每小时的第五分钟)。
- 周期:每隔一段时间后触发。(从现在开始,每隔30分钟触发一次)
执行方式。
- 单机:随机指定一台机器处理整个任务
- 广播:每个机器各自都进行一次这个任务
- Map:将任务拆分成多段让每个机器执行一部分
- MR:拆分成多段各自处理之后还要整合成一份数据。

实现:
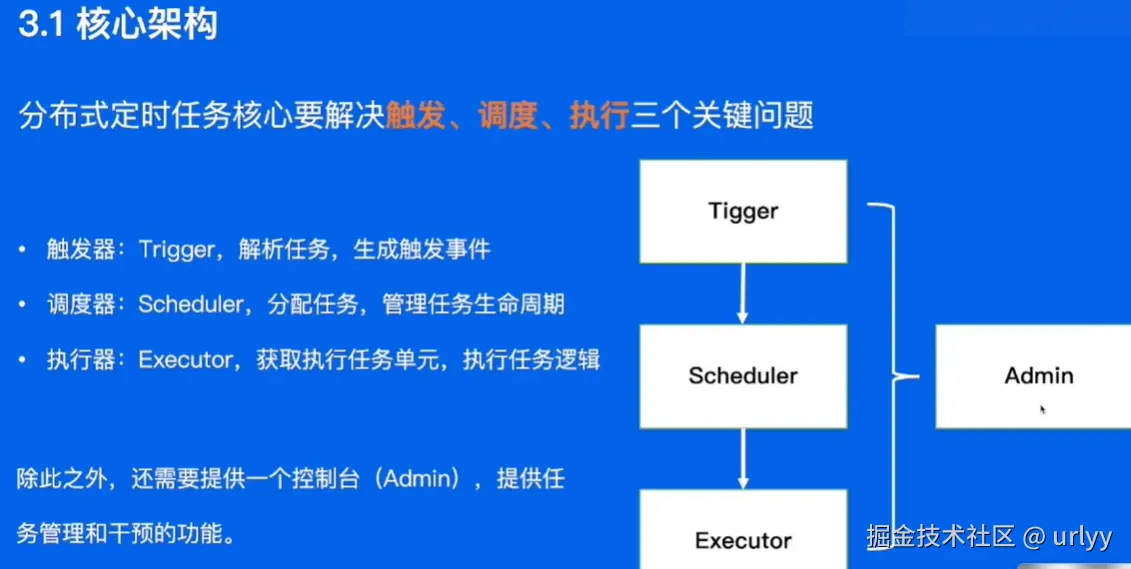
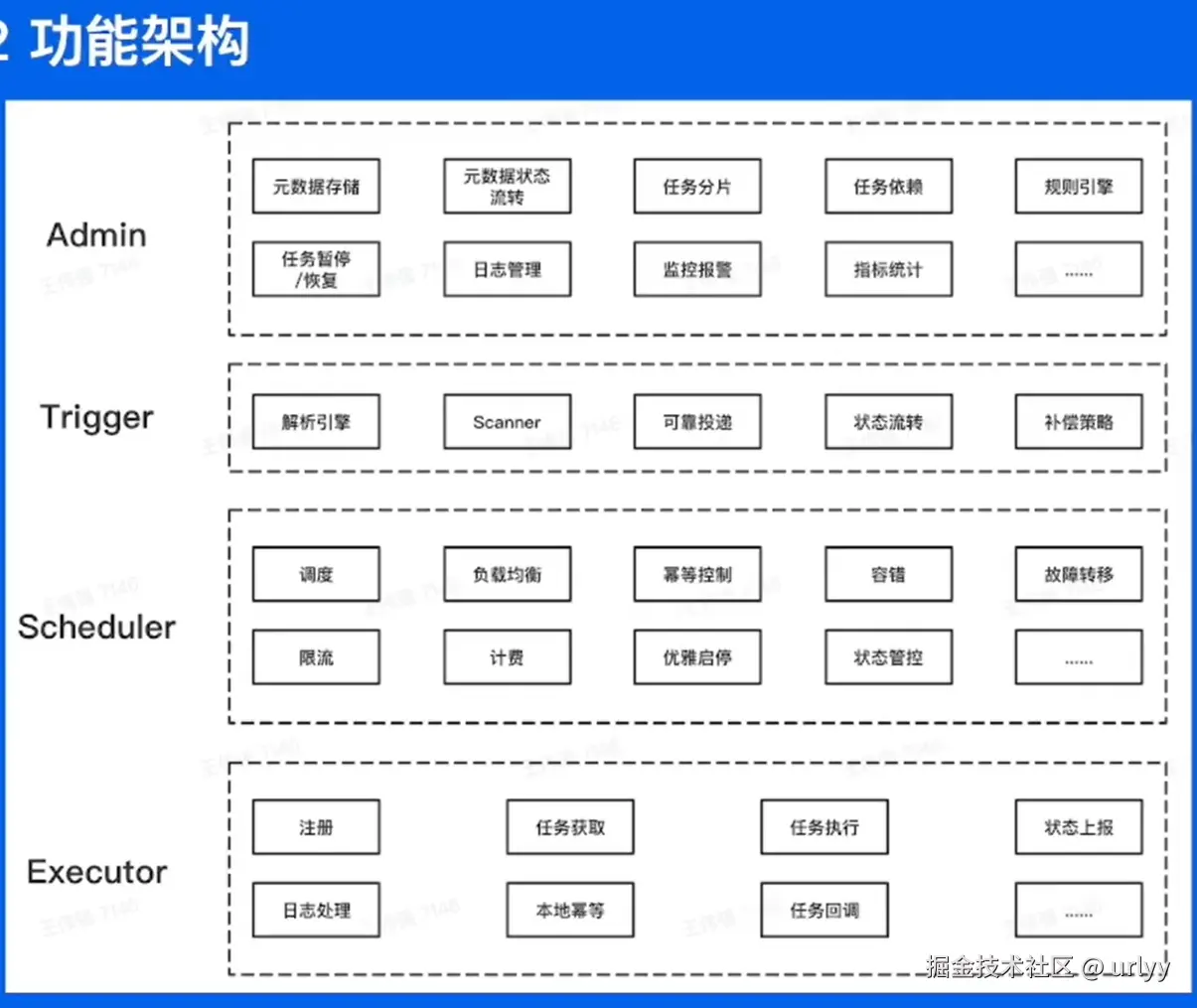
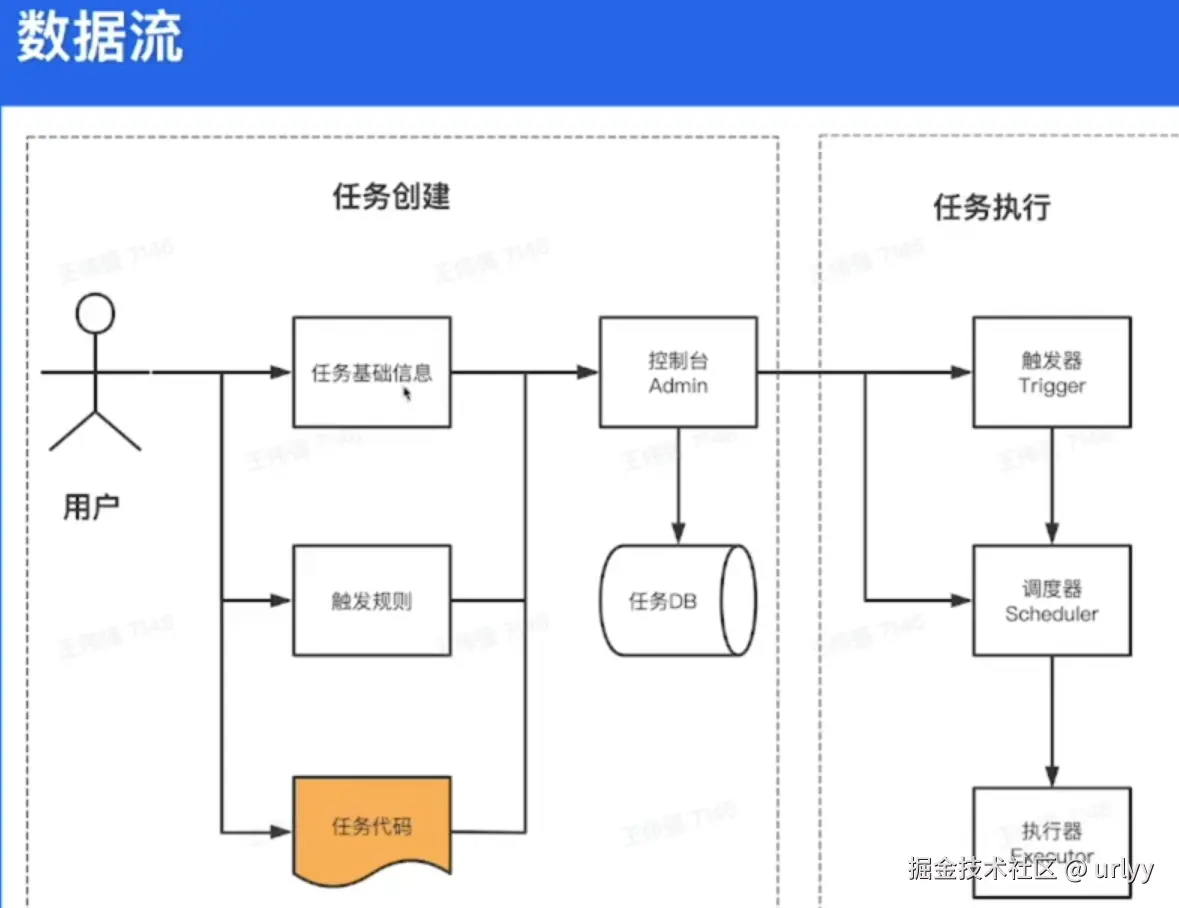
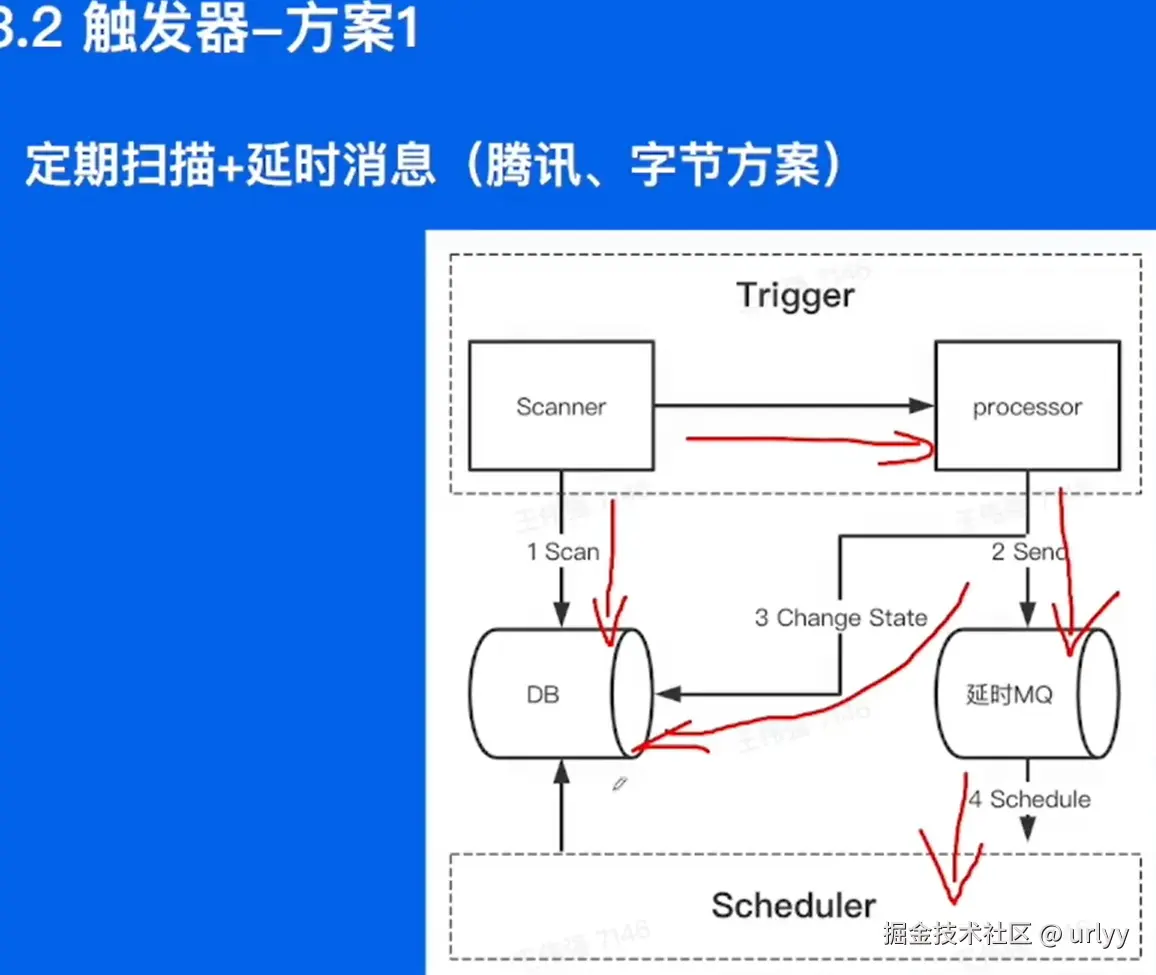
下面的这个时间轮挺有意思,这里讲了方案的演进,即一开始是遍历链表,然后改成查询较快的小顶堆。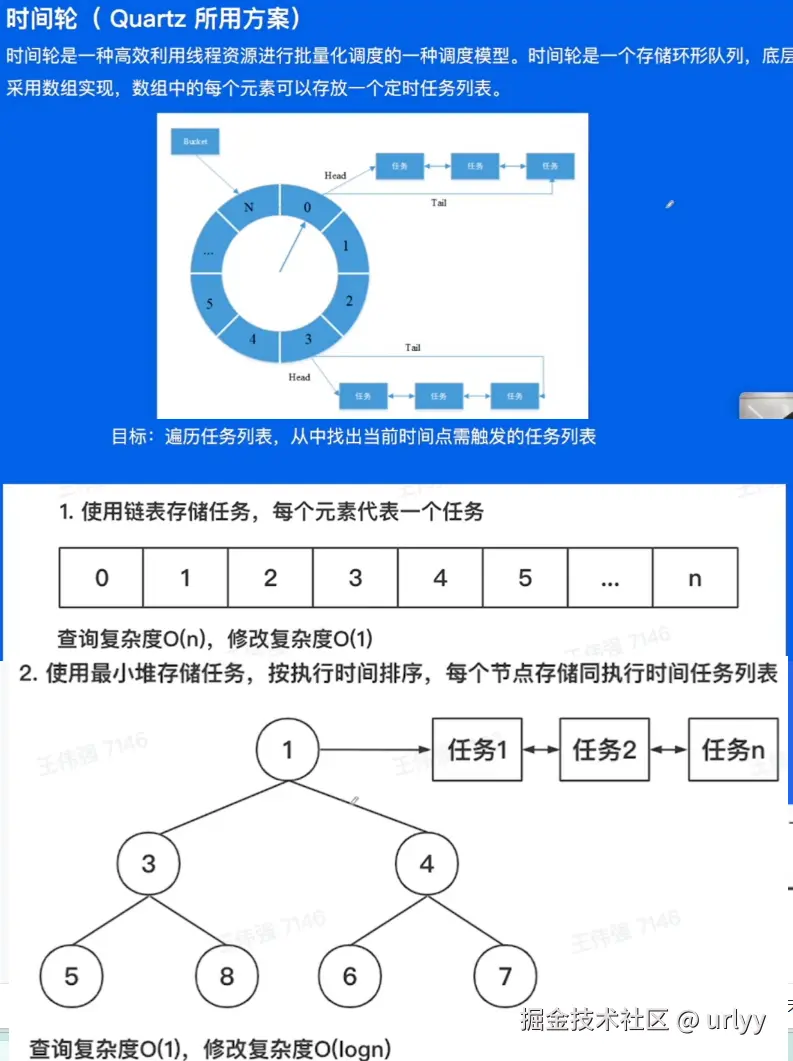
考虑到每个任务都对应60秒中的某格,到达该秒时处理相关的任务。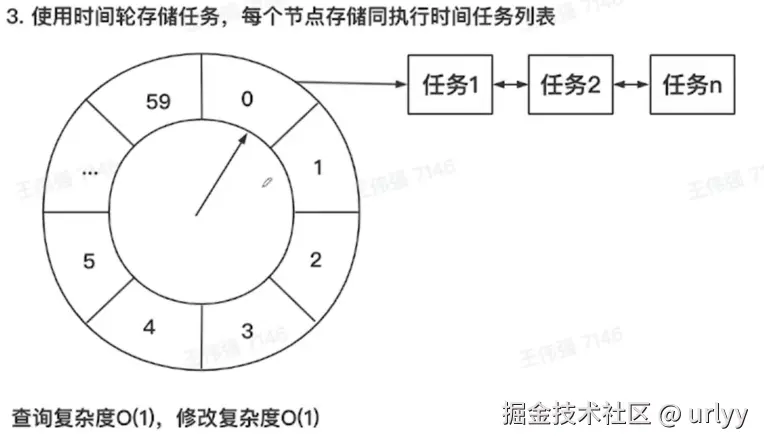
比如一个任务要在每天的02:01:05执行,任务先放在时轮的第二格,每过一个小时时轮走一格,当到达2时将该任务放在分轮的第一格,依次类推,直到秒轮走到他上面之后,执行任务。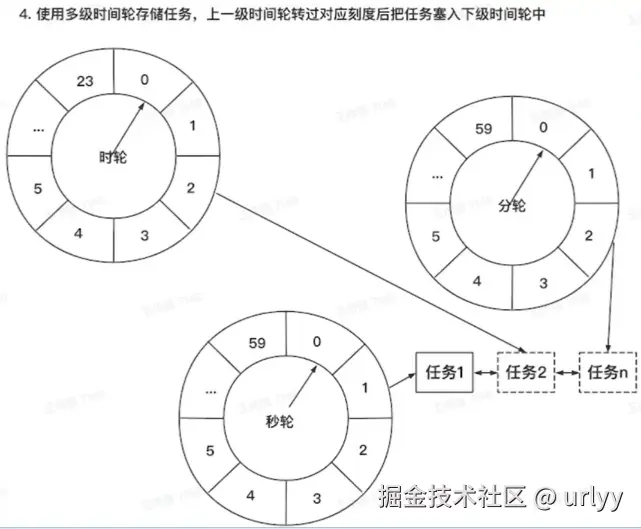

因为无法上手操作感受,大概截个图,以后遇到相关情况再回来看看以及补充。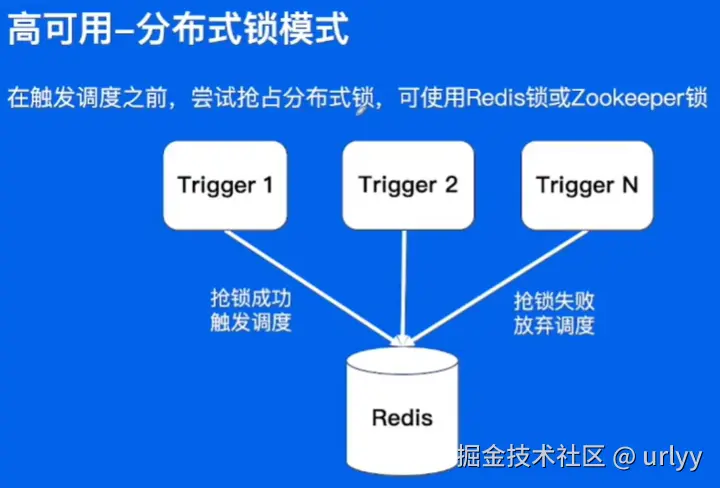


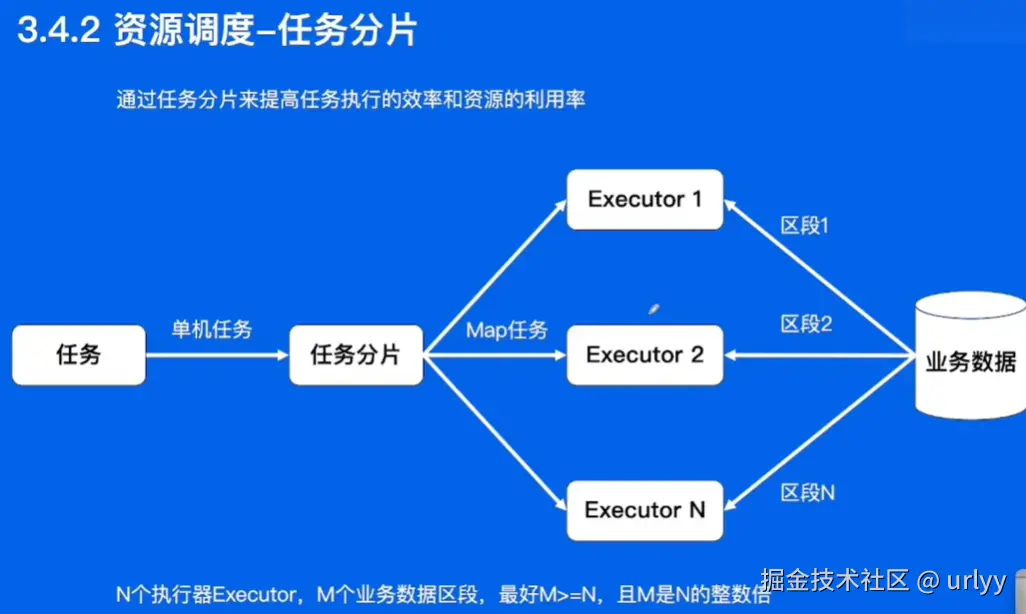
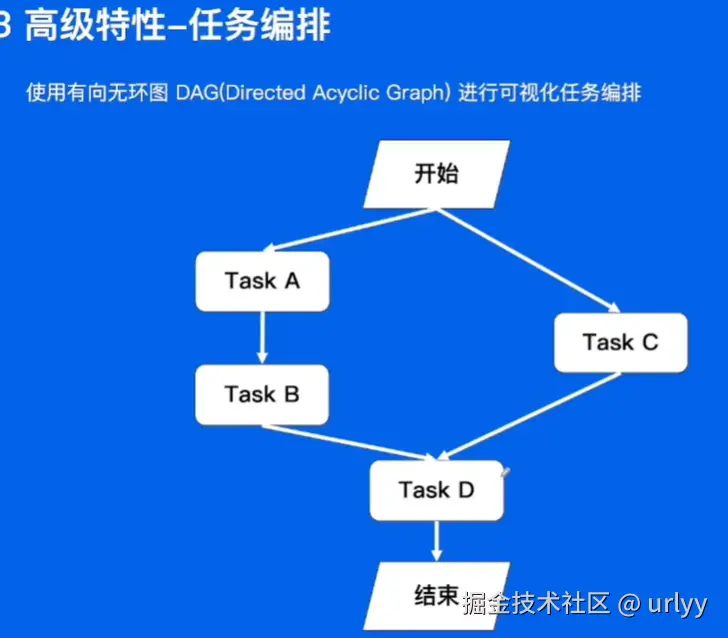
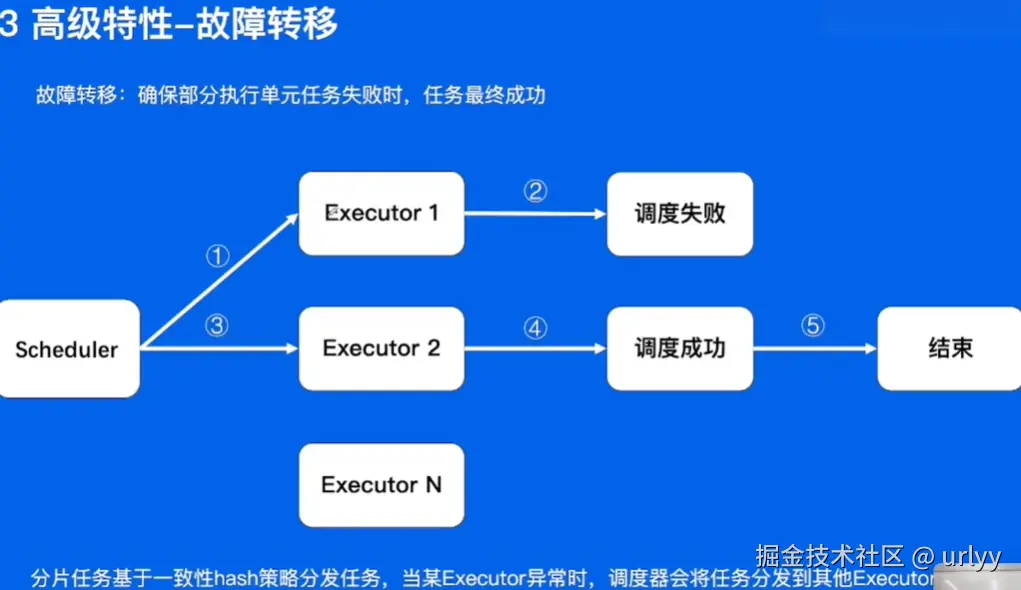
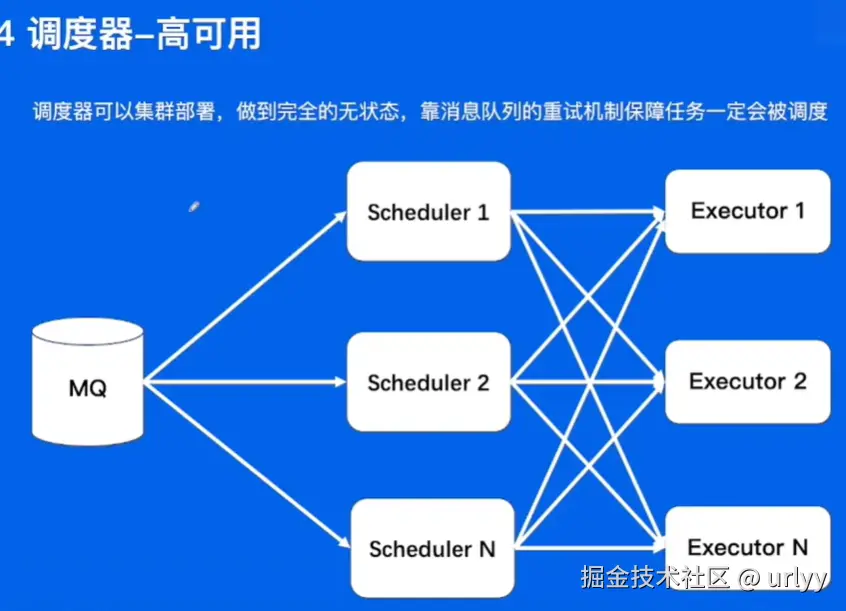
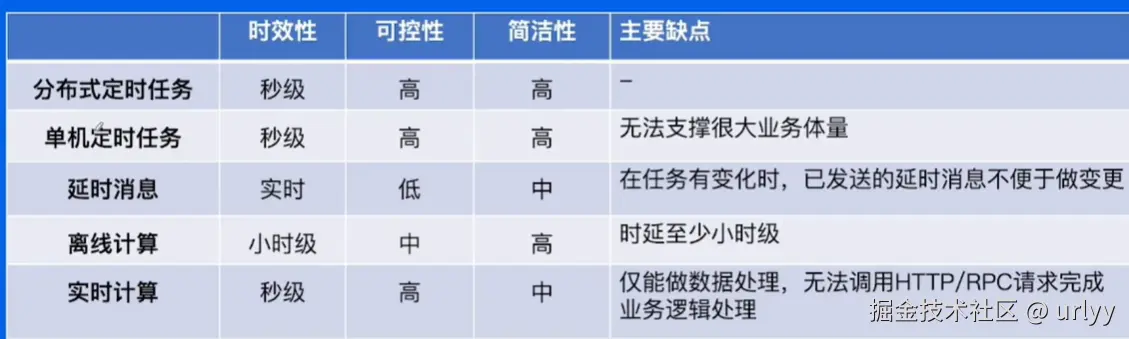
定时任务业务实践
- 标题: 2024字节青训营笔记-消息队列与定时任务
- 作者: urlyy
- 创建于 : 2024-11-24 22:46:41
- 更新于 : 2025-12-21 18:39:57
- 链接: https://urlyy.github.io/2024/11/24/2024字节青训营笔记-消息队列与定时任务/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。